Anlässlich des 10.000 R-Pakets auf CRAN hat eoda ab dem 22.12.2016 bis zum Erscheinen des 10.000 Pakets am 28.01.2017 einen Twitter Account betrieben, der regelmäßig die aktuelle Anzahl der auf CRAN verfügbaren Pakete gepostet hat.
#Rstatsgoes10k – Hello World, it’s 2017-01-28 01:59:03 and currently there are 10000 packages on CRAN.
— eodacelebratesR (@Rstatsgoes10k) 28. Januar 2017
Zum Betrieb dieses Accounts haben wir ein R-Skript geschrieben, das stündlich auf CRAN die aktuelle Anzahl R-Pakete ausgelesen und mit Hilfe der Twitter API sowie dem twitteR Paket einen Tweet mit dem aktuellen Stand abgesendet hat.
Zur Nutzung der Twitter API ist es notwendig, für einen Twitter Account eine entsprechende App zu erstellen.
Dazu auf apps.twitter.com mit dem jeweiligen Account anmelden und unter Create New App das Formular ausfüllen.
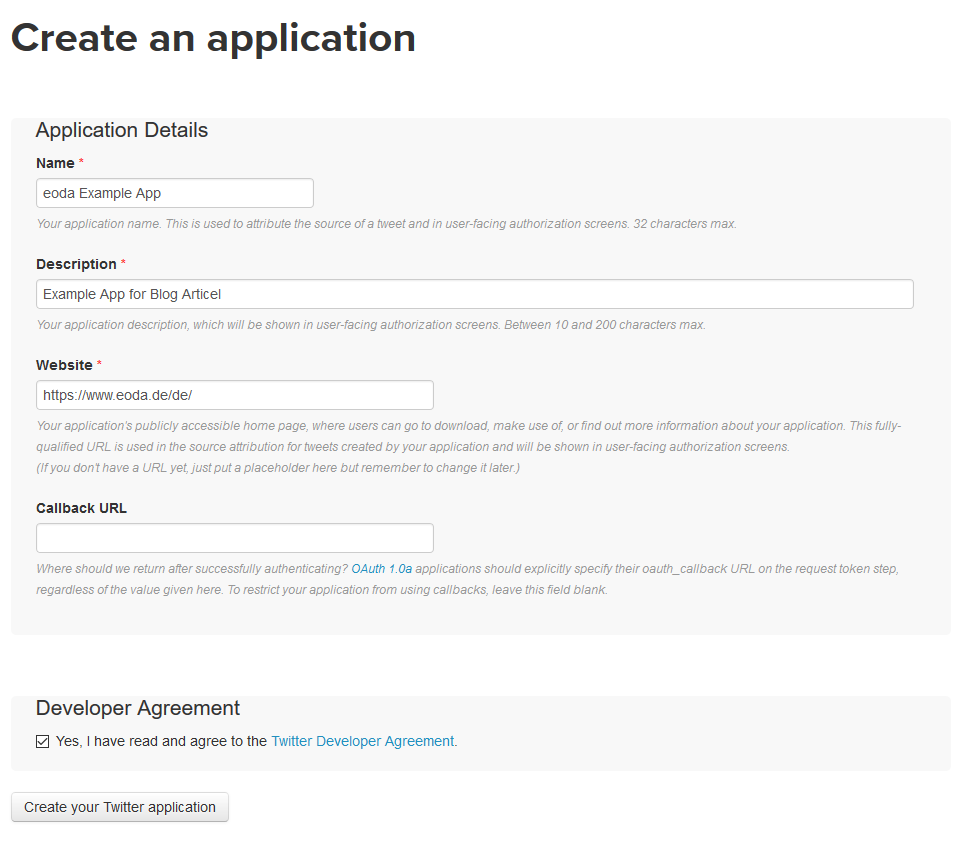
Im nächsten Fenster lassen sich u.a. die Permissions der App steuern, „Read only“, „Read and Write“ oder „Read, Write and Access direct messages“. Damit die App genutzt werden kann, werden die unter dem Reiter Key and Access Tokens verfügbaren bzw. zu generierenden Consumer Key und Consumer Secret sowie Access Token und Access Token Secret, benötigt.
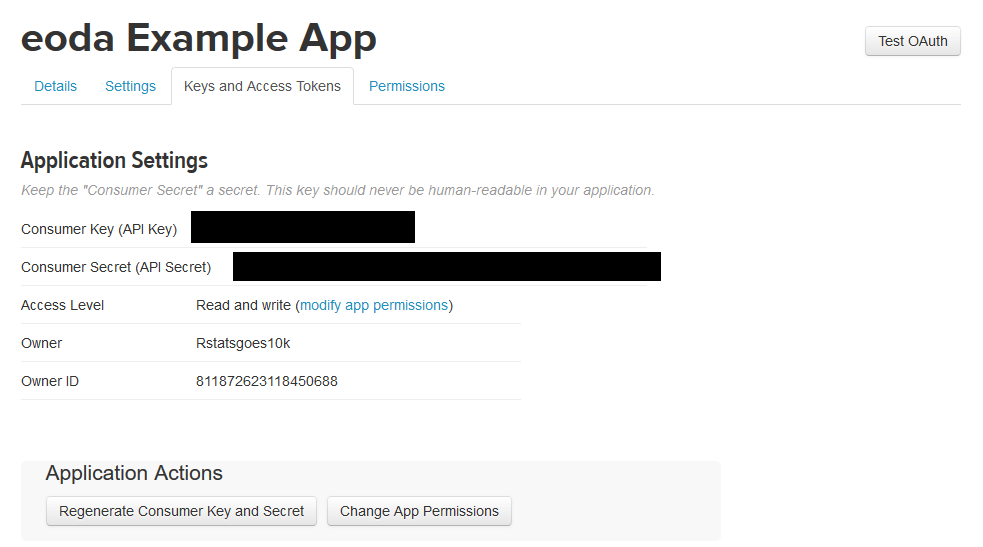
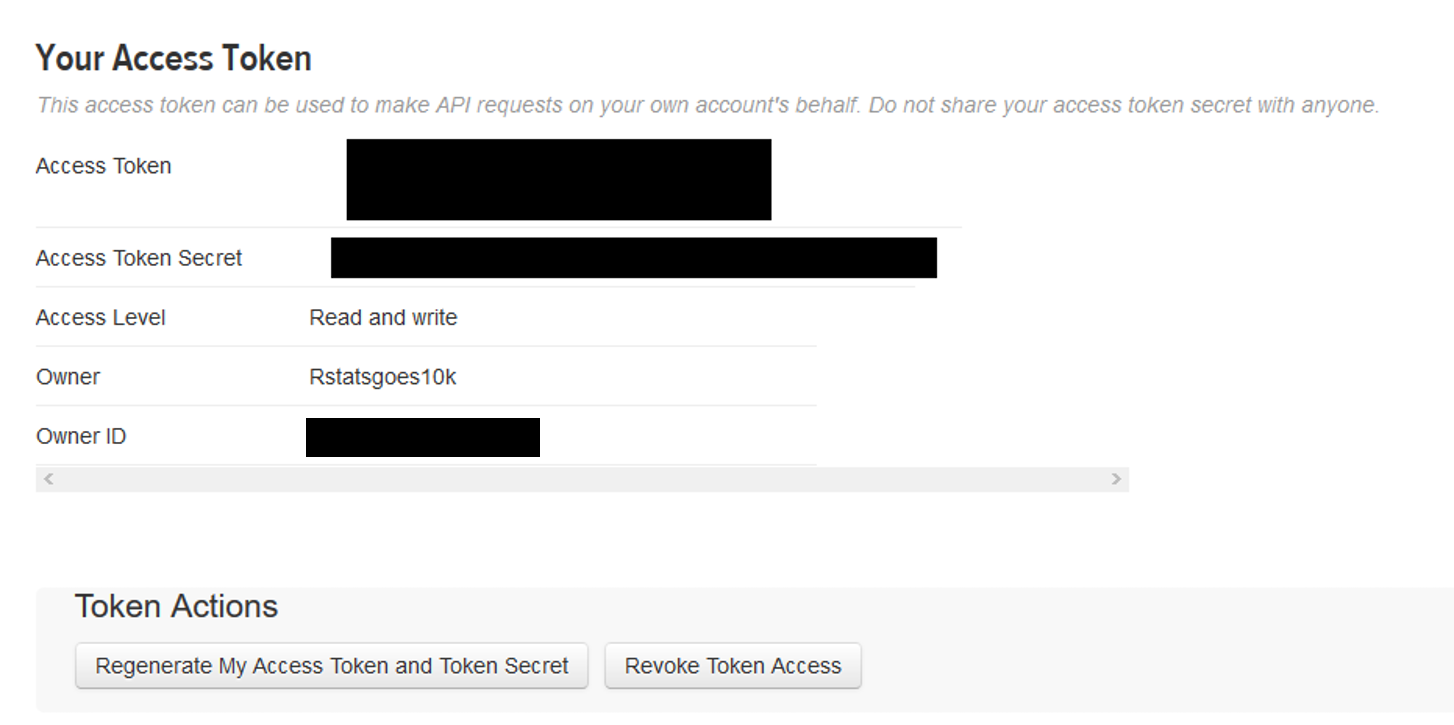
Diese Informationen haben wir in eine extra Datei ausgelagert, um Sie später im R Skript wieder einlesen zu können.
Nach diesen Schritten steht die App zur Nutzung bereit.
Zum Versenden von Tweets aus R heraus, nutzt man die Funktionen setup_twitter_oauth und tweet aus dem twitteR Paket. setup_twitter_oauth kümmert sich um die Authentifizierung und tweet sendet schließlich den entsprechenden Tweet ab.
Wie wir dies für unseren Rstatsgoes10k Account genutzt haben, lässt sich an folgendem R-Skript nachvollziehen:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
# Packages —————————————————————-
library(rvest)
library(stringr)
library(dplyr)
library(twitteR)
# get number of packages ————————————————–
url < – „https://cran.r-project.org/web/packages/“
page <– read_html(url)
n_packages <– page %>%
html_text() %>%
str_extract(„[[:digit:]]* available packages“) %>%
str_extract(„[[:digit:]]*“) %>%
as.numeric()
n_packages_last_time < – read.table(file = „n_packages.csv“,stringsAsFactors = F, sep = „;“)
n_packages_last_time <– n_packages_last_time$V2[nrow(n_packages_last_time)] ## check if news packages are published, new tweet only when number of packages changed if(n_packages > n_packages_last_time) {
# Twitter —————————————————————–
# set up twitter api
api_keys < – read.csv2(„twitter_access.csv“, stringsAsFactors = FALSE)
setup_twitter_oauth(consumer_key = api_keys$consumer_key,
consumer_secret = api_keys$consumer_secret,
access_token = api_keys$access_token,
access_secret = api_keys$access_secret)
time <– Sys.time()
# create tweet
tweet_text <– paste0(„#Rstatsgoes10k – Hello World, it’s „, time, “ and currently there are „, n_packages, “ packages on CRAN. „)
# send tweet
tweet(tweet_text)
# write n to file ———————————————————
n_packages_df <– data.frame(time = Sys.time(), n = n_packages)
write.table(n_packages_df, file = „n_packages.csv“, row.names = FALSE,col.names = FALSE,
append = TRUE, sep = „;“)
}
|