
Data Mesh
Data-Mesh: Dezentralisierung für höhere Datenqualität
Das Data-Mesh Konzept soll die Probleme der zentralen Datensammlung und Auswertung in Data-Warehouse-Systemen und Data Lakes lösen. Aber wie genau funktioniert das?
Data-Warehouses und Data Lakes versprechen durch das zentrale Sammeln von (Roh-)Daten eine leichte Datenspeicherung und eine effektive Grundlage für eine schnelle Datenanalyse, denn Daten sind hier nicht auf einzelne Silos, Systeme, oder Abteilungen verteilt.
Auch wenn die zentrale Datensammlung einen leichten Zugang zu den relevanten Daten schafft, wird die Auswertung dieser Daten immer schwieriger und aufwendiger, je größer die Sammlung ist. Meistens liegt die Verantwortung der Daten bei einzelnen Datenexperten, die diese zentral bearbeiten und auswerten. Aber gerade bei einer immer größer werdenden Anzahl von Daten ist es für eben jene schwierig, auch die Datenqualität zu gewährleisten.
Datenexperten werden vor das Problem gestellt, dass sie oft nicht über das domänen- oder bereichsspezifische Wissen verfügen, um die Daten verschiedener Bereiche für unterschiedliche Anwendungsfälle effektiv auszuwerten. Data-Mesh setzt hier an, indem die Datenproduzenten – die Abteilungen, die die Daten erfassen – direkt mit denen in Verbindung gesetzt werden, die die Daten nutzen wollen, zum Beispiel ein Marketing-Team, welches Sales Daten für eine Kampagne nutzen will, oder Analysten, die die Daten für BI-Zwecke auswerten wollen.
Eine dezentrale Datenarchitektur
Das Data-Mesh Konzept setzt auf eine Dezentralisierung der Datensammlung und -verarbeitung mithilfe einer Self-Service Datenplattform. Diese ermöglicht es domänenspezifischen Teams, ihre Daten eigenständig zu verarbeiten und in eine Form zu bringen, die auch von anderen Teams genutzt werden kann. Das Data-Mesh Konzept wurde zuerst von Zhamak Dehghani, Direktorin für aufkommende Technologien bei dem Technologieunternehmen Thoughtworks, vorgeschlagen und beinhaltet vier Prinzipien1:
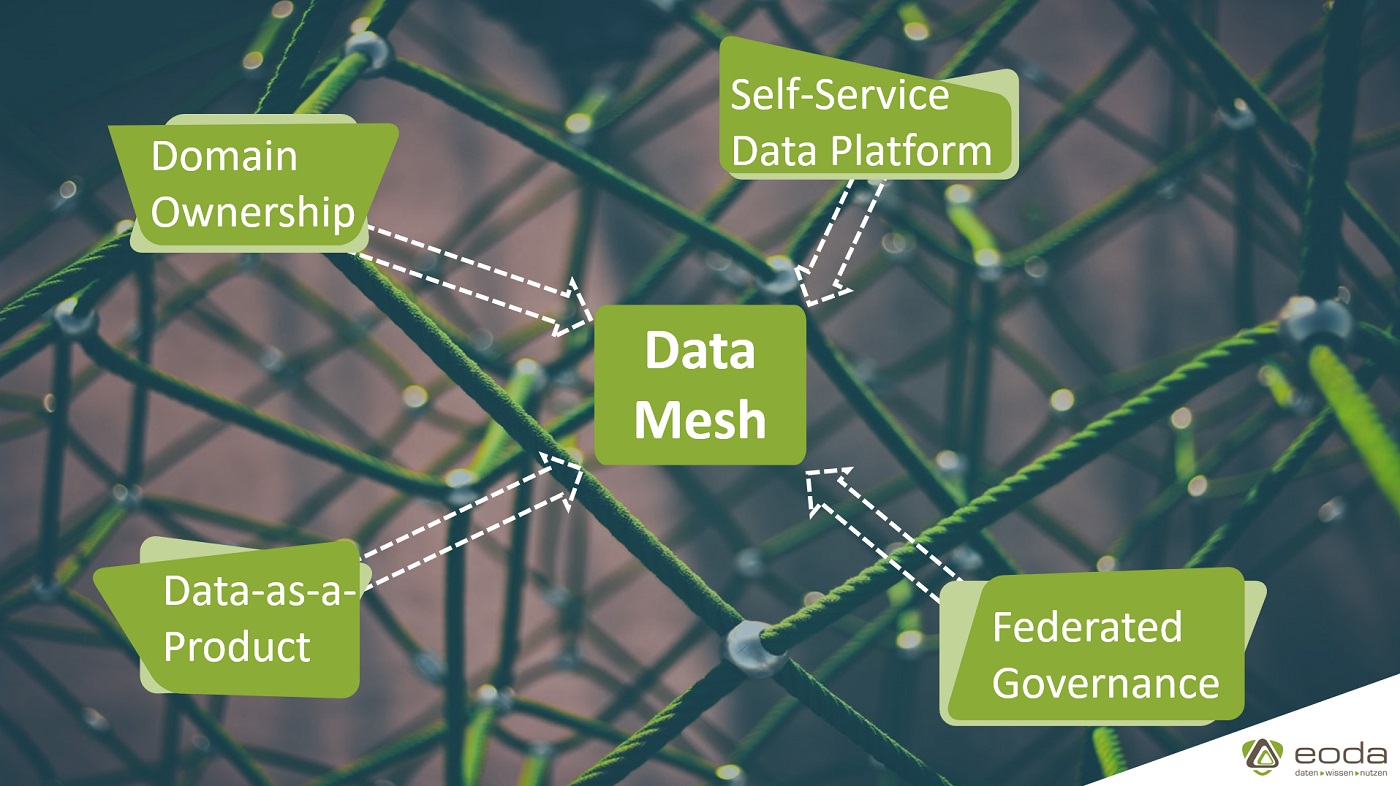
Domain Ownership: Daten werden dezentral von Domain Teams, die für die Daten in ihrem Bereich verantwortlich sind, verwaltet und aufbereitet. Diese Teams entscheiden selbst, welche Daten wichtig sind und weitergegeben werden.
Data-as-a-Product: Daten als Produkt ansehen und mit dieser Annahme an die Verarbeitung und Aufbereitung von Daten herangehen, damit diese nutzbar für andere Teams ohne aufwändiges Datenmanagement zur Verfügung stehen und einen Mehrwert generieren können.
Self-Service Data Platform: Nutzung einer Datenplattform wie YUNA, die das eigenständige, dezentrale Arbeiten mit Daten ermöglicht, inklusive der Auswertung, Darstellung und Bereitstellung der Daten und Ergebnisse für andere Teams. Die Werkzeuge und Funktionen dieser Plattform müssen ohne Hilfe anderer Teams für alle nutzbar sein.
Federated Governance: Es gibt domänenübergreifende Vereinbarungen, die die Zusammenarbeit zwischen den Teams effizient gestalten und langfristig die Datenqualität sichern. Dies beinhaltet beispielsweise auch die Einigung auf abteilungsübergreifend geltende Definitionen, in Form einer Data-Governance-Richtlinie.
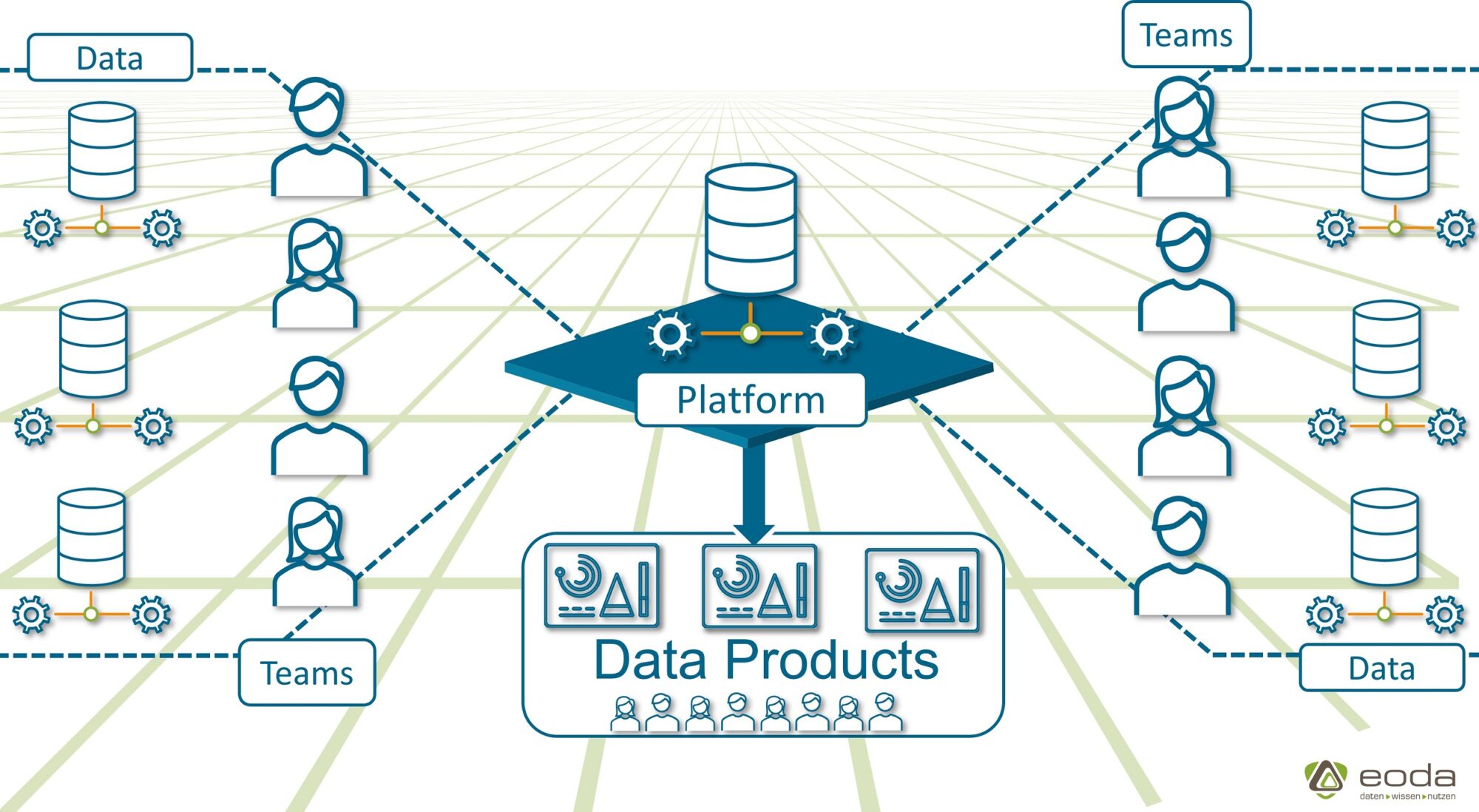
Dadurch, dass die Verantwortung über die Daten bei jenen liegt, die über das domänenspezifische Wissen verfügen und diese durch eine Self-Service Datenplattform befähigt werden, diese Daten zu verarbeiten und zu verbreiten, werden Kompetenzen effektiver genutzt und die Qualität der Daten sichergestellt. Datennutzer können die Daten, die sie benötigen, eigenständig abrufen und weiterverwenden. Sie werden also befähigt, eigenständig Mehrwerte aus den Daten zu generieren.
Diese Möglichkeit zu schaffen, unternehmensweit an den Daten partizipieren zu können, ist für uns einer der zentralen Bausteine für den erfolgreichen Einsatz von Data Science im Unternehmen. Das Konzept Data-Mesh zahlt genau hierauf ein und ist effektiver und skalierbarer als eine zentrale Sammlung in einem Data-Warehouse oder Data Lake. Am Ende entsteht ein Geflecht aus Datenprodukten, die von den Domänenteams anderen zur Verfügung gestellt werden, sodass die Datenprodukte teamübergreifend genutzt werden können.
Die Vorteile des Data-Mesh
Data Science und Data Engineering Teams werden bei der Entwicklung von Modellen, der Analyse der Daten und Pflege der Plattform enorm entlastet, da die Verantwortung der Datenverarbeitung und Datenqualität auf die Domänen Teams übertragen wird. Die Datenqualität wird gesteigert, da die Daten von den Datenproduzenten, die das domänenspezifische Fachwissen haben, selbst ausgewertet werden. Die Domänen Teams haben außerdem aus Produktsicht einen Anreiz, eine hohe Datenqualität sicherzustellen.
Das Erstellen von neuen datengetriebenen Lösungen wird erleichtert, da die Teams dazu befähigt werden, eigenständig ihre Daten auszuwerten. Zudem können Domänen Teams die jeweiligen Datenprodukte anderer nutzen, um ihre eigene Arbeit voranzutreiben. Die Verantwortung über die Daten wird klar auf die jeweiligen Teams aufgeteilt und die Datenanalyse sowie die Entwicklung datengetriebener Lösungen wird beschleunigt. Außerdem ermöglicht das Data-Mesh Konzept, dass mehr Mitarbeitende an dem Prozess der Datenauswertung und –nutzung teilnehmen können, was im Hinblick auf die wachsende Bedeutung von Daten in Unternehmen immer wichtiger wird. Insgesamt führt diese Dezentralisierung zu einer skalierbareren Lösung.
eoda ist Ihr Partner bei der Umsetzung eines Data-Mesh Systems
Sie haben Probleme mit Ihrer aktuellen Dateninfrastruktur oder denken, dass sich bei Ihnen noch ungenutztes Datenpotenzial verbirgt? Wir bieten Ihnen eine etablierte Beratung, Implementierung und Support für Ihre Data Science Infrastruktur. Mit YUNA haben wir eine eigene Data-Science-Plattform entwickelt, mit der Sie eigenständig Ihre Daten bearbeiten, auswerten und visualisieren können.
Wir finden und entwickeln gemeinsam mit Ihnen die optimale Datenarchitektur für Ihr Unternehmen. Sprechen Sie uns noch heute an!
1 https://www.thoughtworks.com/de-de/what-we-do/data-and-ai/data-mesh
Lassen Sie sich von uns beraten!

Infrastruktur:
Konzept, Aufbau und Betrieb aus einer Hand
Performante und verlässliche Infrastrukturen sind das Fundament für datenbasierte Mehrwerte. Mit über 10 Jahren Erfahrung begleiten wir Sie bei der Planung, Umsetzung und dem Betrieb von IT-Infrastrukturen
Case Study:
Aufbau einer Analyseumgebung für Konzernstrukturen
Beratung, Implementierung, Schulung und Support: Wir haben für REWE eine leistungsfähige Analyseumgebung rund um den produktiven Einsatz der Data-Science-Sprache R aufgebaut

Blog:
Was ist ein Data Lake?
Was in der Natur mündende Flüsse sowie Regen oder Schnee sind, sind bei einem Data Lake die unterschiedlichen Datenquellen, die ihn füllen. Zahlen- oder textbasierte Daten, Bilder, Videos: Der Data Lake kann ein Sammelbecken für unterschiedlichste Datenformate sein.

Data Driven Software:
YUNA – Data Science Plattform
Modulare und belastbare Architektur, flexibles Dashboard – YUNA deckt alle relevanten Schritte zur Konzeption, Ausführung und Verwaltung digitaler Services und Analysen ab!