Die Entwicklung einer Künstlichen Intelligenz ist heute das Mittel der Wahl, um Probleme aus den verschiedensten Bereichen zu lösen. Smart Homes und selbstfahrende Autos sind lediglich zwei Beispiele, die dem Menschen das Leben erleichtern sollen. Eine Frage, die beim Thema KI stets präsent ist, ist die Frage, ob die Entscheidungen der KI auch tatsächlich den Wünschen des Nutzers bzw. des Entwicklers entsprechen und ob die KI tatsächlich bessere Entscheidungen trifft als ein Mensch es in der jeweiligen Situation tun würde. Die Entwicklung einer KI wird somit ständig begleitet vom Vergleich zwischen Mensch und Maschine. Ein Bereich, der dazu einlädt, die Leistungen von Menschen und KIs – oder verschiedener KIs untereinander – zu vergleichen, ist der Wettkampf in Form eines Spiels. Da ein Spiel feste Regeln hat und alle möglichen Entscheidungen grundsätzlich bekannt sind, kann man den Lernfortschritt und -erfolg des Spielers leicht untersuchen und bewerten. Das Ziel ist dabei immer gleich: Die KI soll unter den fest vorgegebenen Voraussetzungen ein möglichst gutes Ergebnis erzielen. Eine Methode, die dafür in den letzten Jahren an Popularität gewonnen und bereits beachtliche Erfolge erzielt hat, ist das Reinforcement Learning.

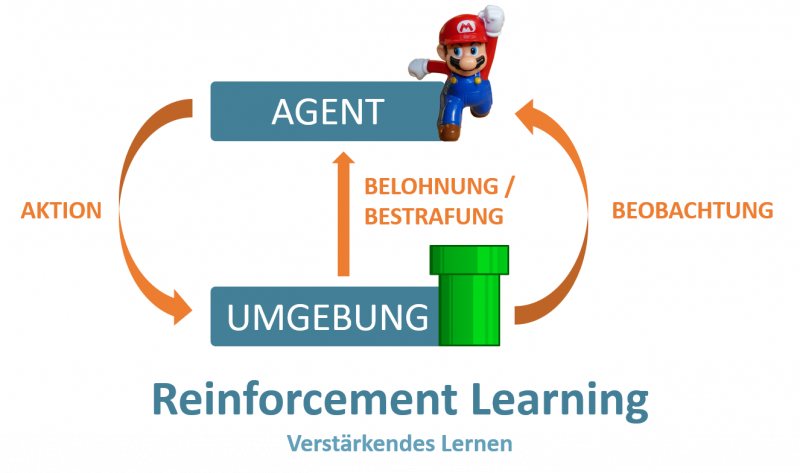
Neben den bereits etablierten Klassen an Machine-Learning-Algorithmen des Supervised und Unsupervised Learnings, bietet das Reinforcement Learning einen neuen Ansatz: Die KI soll in einer bestimmten Situation aufgrund der zu erwartenden Folgen eine optimale Entscheidung treffen. Dabei soll die KI auf Basis ihrer Erfahrungen lernen, Situationen richtig zu bewerten und die Folgen besser abzuschätzen. „Reinforcement“ bezieht sich dabei auf das Feedback, das die KI zu ihren Entscheidungen erhält (bspw. das Gewinnen von Punkten, nach einer bestimmten Spielentscheidung oder das Erfahren einer Bestrafung), welches wiederum von der KI genutzt wird, um die Qualität der zukünftigen Entscheidungen besser einzuschätzen.
Schach, Go und Shogi – Die KI als Großmeister
Strategische Brettspiele dienen als anschauliches Beispiel, um die Funktionsweise des Reinforcement Learnings zu verdeutlichen. Sie bieten aufgrund ihres fest definierten Regelwerks optimale Rahmenbedingungen, um eine KI zu trainieren. Zum einen sind Spiele wie Schach oder Shogi allesamt rundenbasiert, sodass der Spieler das Spielfeld und potenzielle Zugfolgen analysieren kann, ohne dass sich die Umgebung ändert. Zum anderen steht dem Spieler zu jedem Zeitpunkt und in jedem Spiel die Gesamtheit an Informationen zur Verfügung. Das bedeutet nicht nur, dass der Spieler (theoretisch) jede beliebige mögliche Zugfolge analysieren kann, sondern vor allem auch, dass der Spieler das Gelernte abstrahieren kann. Wählt der Spieler in einer bestimmten Situation einen schlechten Zug, so kann er daraus lernen und wird in den darauffolgenden Spielen versuchen, einen solchen Zug in einer gleichen (oder ähnlichen Situation) zu vermeiden. Tatsächlich konnten mit Reinforcement Learning trainierte KIs erstaunliche Erfolge in den klassischen Strategiespielen Schach, Go und Shogi erzielen. So gelang es allen voran der KI „AlphaZero“ (entwickelt vom Unternehmen DeepMind, das vor einigen Jahren von Google übernommen wurde), die auf Grundlage der Regeln durch das Spielen gegen sich selbst trainiert wurde, Erfolge gegen State-of-the-Art Engines für die jeweiligen Brettspiele zu erzielen. In einem 100 Partien umfassenden Match gegen die aktuell stärkste Schachengine („Stockfish“, mehrfacher Sieger der Top Chess Engine Championship) gelang es AlphaZero 28 Siege und 72 Remis zu erzielen. Obwohl das Match unter nachteiligen Bedingungen für Stockfish ausgetragen wurde (stark eingeschränkte Bedenkzeit, geringe Rechenkapazität), ist es beachtlich, dass eine KI, die lediglich durch das Spielen gegen sich selbst ein neuronales Netzwerk optimiert und seine Entscheidung mittels Monte-Carlo Suchverfahren trifft, auf einem Level mit einer Top-Engine ist. Zumal diese ihre Spielentscheidungen durch das Durchforsten riesiger Suchbäume und von Schachgroßmeistern definierter Heuristiken trifft. Ein weiterer Vergleich zeigt, dass die KI im Hinblick auf die Rechenzeit effizienter entscheidet: So berechnet AlphaZero ca. 80.000 Positionen pro Sekunde – Stockfish hingegen um die 70 Millionen.
Von Super Mario zu Starcraft II
Neben strategiebasierten Brettspielen bietet sich Reinforcement Learning ebenfalls für das Spielen von Videospielen an. Videospiele, die eine geringe Anzahl an Steuerungsmöglichkeiten – ein klassisches Jump’n’Run bietet die Möglichkeit nach links/rechts zu laufen und zu springen – und fest definierte Regeln haben (zum Beispiel der Verlust von Punkten beim Springen in den Abgrund oder beim Laufen gegen eine Wand), bieten eine hervorragende Grundlage, um eine KI mittels Reinforcement Learning zu trainieren. Somit ist es relativ einfach, eine KI zu entwickeln, die beispielsweise lernt, ein Level des Jump’n’Run Klassikers „Super Mario Bros.“ zu spielen. Der Lernprozess hat dabei große Ähnlichkeiten zum menschlichen Lernprozess. Die KI wird zunächst einige Male auf einen Abgrund zulaufen ohne zu Springen und somit verlieren. Durch die darauffolgende Bestrafung und genügend zufällige Sprünge lernt die KI, dass das Springen über einen Abgrund die erwartete Punktzahl maximiert. Analog dazu ist es möglich, einer KI in kurzer Zeit das Spielen von simplen Spielen wie Pong oder einfachen Rennspielen beizubringen.
Es ist sogar möglich eine KI zu entwickeln, die in der Lage ist, weitaus komplexere Videospiele zu meistern. So entwickelte DeepMind eine KI namens „AlphaStar“, deren Aufgabe es ist, das Echtzeitstrategiespiel „Starcraft II“ zu spielen, das einen Wettkampf zwischen zwei Spielern beinhaltet. Im Gegensatz zu klassischen Strategiespielen wie Schach oder Go ist Starcraft II deutlich komplexer. Zum einen passieren alle Aktionen in Echtzeit – also nicht rundenbasiert – und geben der KI somit nicht die Möglichkeit, eine längere Zeit über eine bestimmte Aktion nachzudenken. Zum anderen sieht ein Starcraft II Spieler niemals die komplette Karte, sondern muss diese aktiv erkunden. Dies schränkt die zur Entscheidungsfindung verfügbaren Informationen deutlich ein. Doch auch bei Starcraft II ist es möglich, jede Entscheidung auf Basis der zu erwartenden Folgen zu bewerten. Durch Reinforcement Learning kann die KI lernen, wie man bestimmte Strategien kontert, welche Art von Einheiten eine passende Antwort auf gegnerische Einheiten sind und ob in der jeweiligen Spielphase eine offensive oder defensive Strategie vielversprechender ist. AlphaStar wurde zu Beginn vor allem mithilfe von aufgezeichneten Spielen zwischen Menschen trainiert, um eine grundsätzlich vernünftige Spielweise zu lernen. Im weiteren Verlauf des Trainingsprozess traten verschiedene Versionen der KI im Rahmen eines Ligaformats gegeneinander an und entwickelten sich dadurch unabhängig voneinander weiter. Das Ergebnis ist auch hier eine KI, die das Spiel auf einem professionellen Level beherrscht. So gelang es AlphaStar vor einigen Monaten, erstmals gegen professionelle Starcraft II Spieler zu gewinnen.
Anwendungen in der realen Welt – Autofahren durch Reinforcement Learning
Neben dem Spielen hat das Reinforcement Learning jedoch auch Potenzial, in realen Problemstellungen von Nutzen zu sein. Es ist beispielsweise möglich, selbstfahrende Autos mithilfe von Reinforcement Learning zu trainieren. Durch vordefinierte Regeln (Einhalten der Spurbegrenzung, Sicherheitsabstand, etc.) kann die KI lernen, welche Aktionen in einer bestimmten Situation angemessen sind: Überquert die KI Spurbegrenzung bei gerader Strecke, wird die sie „bestraft“ und lernt somit bei gerader Strecke nicht zu lenken. Erfährt die KI beim Überfahren einer roten Ampel oft genug eine Bestrafung, wird sie lernen, an einer roten Ampel anzuhalten. Entscheidend hierbei ist die klare Definition von Belohnungen und Bestrafungen für bestimmte Aktionen.
Eine weitere Voraussetzung für eine verlässliche KI, ist eine große Datenmenge an Erfahrungen. Anders als beim Supervised Learning, bei dem die Daten bereits mit einem Label versehen sind, muss die KI eine Folge von Aktionen zunächst selbst ausführen, um sie dann anhand des erhaltenen Feedbacks bewerten zu können. Je komplexer die Bedingungen sind, desto mehr Erfahrungen muss die KI machen, um eine große Menge an Situationen korrekt bewerten zu können. Nichtsdestotrotz ist vor allem die Tatsache, dass die KI selbst lernt und nicht anhand von vorgegebenen Regeln entscheidet im Hinblick auf die Selbständigkeit sehr vielversprechend. So kann die KI mithilfe von Reinforcement Learning bestimmte Verhaltensweisen besser generalisieren und auf neue Situationen anwenden.
Erfahren Sie mehr.