
RAG in der Praxis: Aufbau einer RAG-Pipeline für einen Chatbot
Eine RAG-Pipeline (Retrieval-Augmented Generation) besteht aus mehreren essenziellen Komponenten, die in enger Zusammenarbeit für die Generierung präziser und relevanter Antworten sorgen. In diesem Artikel stellen wir die grundlegenden Bestandteile eines RAG-Systems vor und zeigen anhand eines praktischen Beispiels, wie wir einen Chatbot entwickelt haben, der Fragen zu unternehmensinternen Datenschutz- und Datensicherheitsunterlagen beantwortet.

RAG in der Praxis: Aufbau einer RAG-Pipeline für einen Chatbot
Eine RAG-Pipeline (Retrieval-Augmented Generation) besteht aus mehreren essenziellen Komponenten, die in enger Zusammenarbeit für die Generierung präziser und relevanter Antworten sorgen. In diesem Artikel stellen wir die grundlegenden Bestandteile eines RAG-Systems vor und zeigen anhand eines praktischen Beispiels, wie wir einen Chatbot entwickelt haben, der Fragen zu unternehmensinternen Datenschutz- und Datensicherheitsunterlagen beantwortet.

Zum Blogartikel „Retrieval Augmented Generation (RAG)„
Zum Blogartikel „RAG: 5 Anwendungsfälle für die Verbindung aus Generative AI und Unternehmenswissen“
Bei der Implementierung verwenden wir die Programmiersprache Python und stützen uns auf das Open Source Orchestrierungs-Framework LangChain. Modelle nutzen wir von OpenAI und HuggingFace.
Welche Komponenten sind essenziell in einer RAG-Pipeline?
Die folgende Beschreibung des Workflows bezieht sich auf eine textbezogene Anwendung von RAG. Nichtsdestotrotz besteht auch die Möglichkeit, mit anderen Arten von Dokumenten – beispielsweise Bildern – als Datenquelle zu arbeiten.
Nahezu alle Komponenten der Pipeline können ausgetauscht werden. Daher verwenden wir unsere Datenschutz- und Datensicherheits-QA-Chatbot auch mit verschiedenen Modellen und Algorithmen.
Aufbau einer RAG-Pipeline
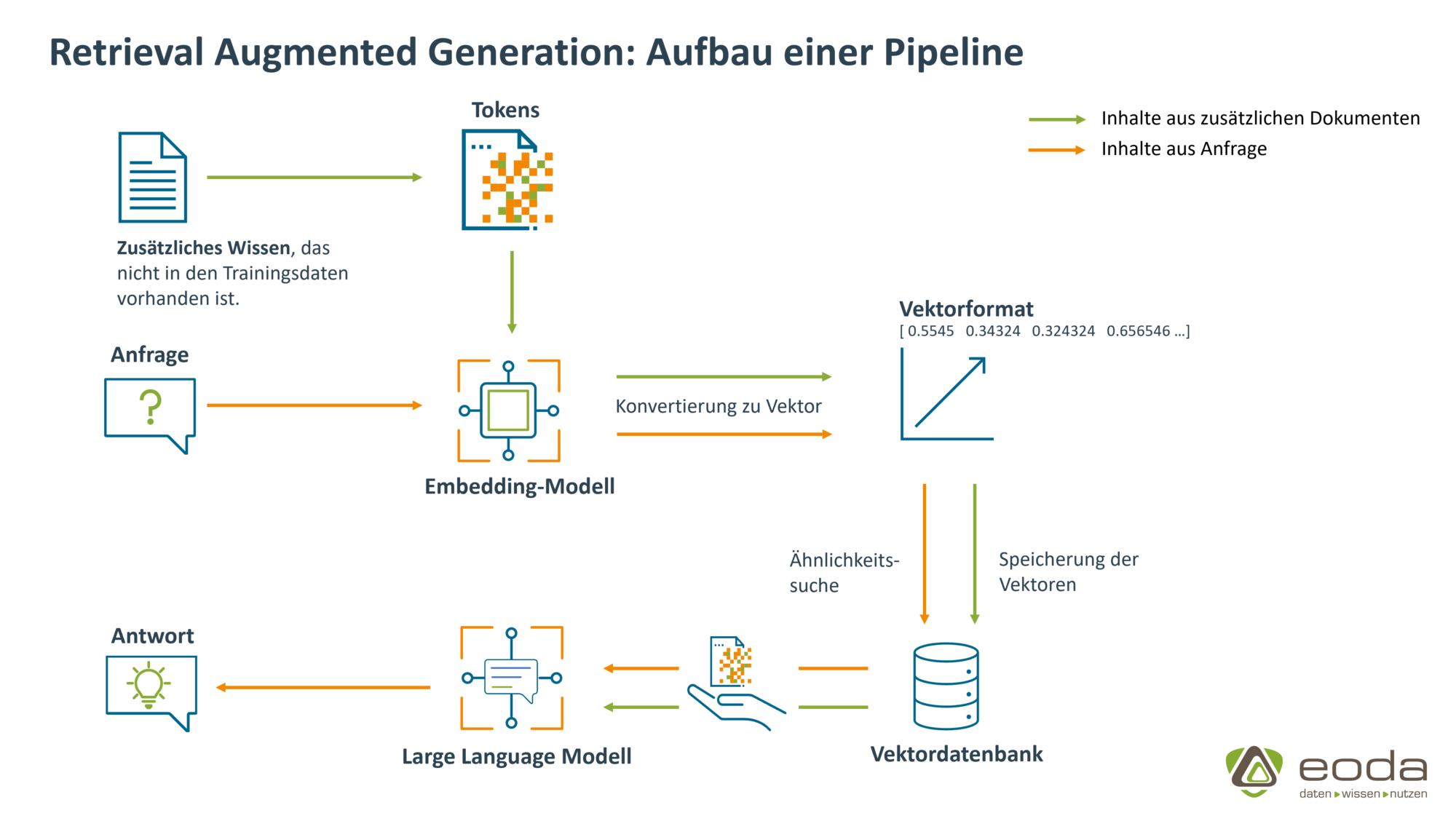
Die Basis – eine externe Wissensquelle
Starten wir mit dem „Herzstück“, den externen Dokumenten bzw. Informationen, die die Basis für die Antwortgenerierung des LLMs bilden und oftmals der Grund sind, weshalb RAG eingesetzt werden soll.
Unsere externen Daten bilden die unternehmensinternen Datenschutz- und Datensicherheitsunterlagen. Sie liegen als PDF-Dateien vor und werden mithilfe eines PDF-Loaders eingelesen und in das im weiteren benötigte LangChain-Dokumentenformat umgewandelt. In diesem Format speichern wir die Daten nun, um sie für alle weiteren Schritte zugänglich zu machen.
Erste Verarbeitungsschritte – die Tokenisierung des Textes
Um sicherzustellen, dass die semantische Bedeutung des Textinputs korrekt vom Embedding-Modell erfasst wird, ist eine sorgfältige Vorverarbeitung erforderlich. Hier sind die Schritte im Detail:
1. Textaufteilung mit einem Text Splitter:
Der Text wird zunächst in kleinere Abschnitte, sogenannte Chunks, unterteilt, um sicherzustellen, dass das Modell den Input verarbeiten kann. Abhängig vom Modell können beispielsweise bis zu 16.000 Token in einem Prompt verarbeitet werden. Der Prompt enthält die für die Frage relevantesten Textabschnitte, die Frage selbst und allgemeine Anweisungen. Chunks haben daher typischerweise eine Länge von 1.000 bis 2.000 Token. Jeder Chunk soll einen inhaltlich sinnvollen (Teil-)Abschnitt des Textes darstellen, wie beispielsweise einen Satz oder Absatz. So geht keine Kontextinformation verloren.
Einige Beispiele für Text Splitter sind:
- Character Text Splitting: Unterteilung nach einer bestimmten Zeichenanzahl
- Recursive Character Text Splitting: Unterteilung mit dem Versuch, semantische Einheiten intakt zu halten und die Struktur des Textes nicht allzu sehr zu zerstören
- Naive Sentence Splitting: Unterteilung an dem Punkt-Symbol als Satzzeichen
- HTML Header Text Splitting: Unterteilung an HTML-Header
2. Tokenisierung mit einem Tokenizer:
Jeder Abschnitt wird anschließend vom Tokenizer in einzelne Tokens zerlegt. Dies bedeutet, dass der Text in Wörter, Subwörter oder Zeichen aufgeteilt wird, je nach dem verwendeten Tokenisierungsalgorithmus. OpenAIs Tokenizer für GPT-4 zerlegt den Anfang dieses Absatzes beispielsweise in folgende Tokens: “J|eder| Abs|chnitt| wird”. Häufige Wörter wie “wird” bleiben in ihrer Gänze beibehalten, während seltenere Wörter in Teile oder einzelne Buchstaben zerlegt werden. In deutschsprachigem Text entsprechen 100 Tokens durchschnittlich etwa 50 Wörtern.
3. Zuweisung von Token-IDs
Jedem Token wird eine eindeutige numerische Token-ID zugewiesen. Diese IDs dienen als Eingabe für das Embedding-Modell und ermöglichen es dem Modell, die Bedeutung jedes Tokens zu erfassen.
Für die Umwandlung der Datenschutz- und Datensicherheitsunterlagen in Tokens nutzen wir den rekursiven Character-Text-Splitter. Der Text Splitter bietet die Möglichkeit, die maximale Zeichenanzahl pro Chunk (chunk size) sowie die Anzahl der Zeichen, die sich in den aufeinanderfolgenden Chunks überlappen (chunk overlap), festzulegen. Zudem können bestimmte Separatoren definiert werden, die im Hinblick auf den semantischen Kontext von Bedeutung sind – zum Beispiel Leerzeichen oder Punkte.
Der RecursiveCharacterTextSplitter teilt den Text rekursiv in immer kleiner werdende Abschnitte auf – beginnend bei den allgemeinsten Trennzeichen wie Absätzen. Er verwendet eine hierarchische Liste an Trennzeichen, die beispielweise wie folgt aussieht: [„\n\n“, „\n“, “ „, „“].
Was sind gute Werte für chunk size und chunk overlap?
Es ist nicht ungewöhnlich, wenn die Frage nach einem optimalen Hyperparameterwert aufkommt. Eine one-size-fits-all Lösung gibt es hierfür nicht, allerdings sind folgende Punkte zu berücksichtigen:
- Struktur der Dokumente: Finden sich klare abgegrenzte Abschnitte, Kapitel oder Themenbereiche? Werden Überschriften und Unterüberschriften verwendet? Sind Listen, Tabellen oder andere Formatierungselemente in den Dokumenten?
- Länge der Dokumente: Handelt es sich um lange Dokumente wie beispielsweise Bücher oder akademische Artikel? Oder doch eher um kürzere Dokumente wie beispielsweise Social Media Posts oder Kundenbewertungen?
- LLM-Kontextlänge: Wie viele Tokens kann das Sprachmodell in einem Durchlauf verarbeiten?
Darauf aufbauend gilt es auszuprobieren, welche Werte empirisch gut funktionieren.
Unser Chatbot arbeitet mit 2000 Characters pro Abschnitt und einer Überlappung von jeweils 100 Characters.
Von Text zu Zahl – Darstellung als Vektoren
Da Computer ausschließlich mit Zahlen arbeiten, werden die Tokens nicht als Klartext weiterverarbeitet. Wie bereits erwähnt, wird jedem Token eine eindeutige Token-ID zugewiesen. Diese IDs können dann von einem Embedding Modell in Vektoren – die sogenannten Embeddings – umgewandelt werden. Übrigens basieren alle maschinellen Lernalgorithmen – einschließlich der Neuronalen Netze, die die Sprachmodelle antreiben – auf Berechnungen mit numerischen Daten.
Zahlen mit semantischer Bedeutung? – Das Embedding Modell
Jedes Embedding Modell generiert den sogenannten „embedding space“ (hochdimensionaler Vektorraum), in welchem die Vektoren bzw. Embeddings mit ähnlicher Bedeutung nahe beieinander angeordnet werden. Somit bleibt die semantische Bedeutung der Tokens durch ihre Vektoren, also ihre numerische Repräsentation, erhalten.
Aktuelle Embedding Modelle basieren auf großen neuronalen Netzwerk-Architekturen, die mit großen Textkorpora – vereinfacht gesagt einer großen Sammlung von Texten – trainiert wurden und ein breites Spektrum an semantischen und syntaktischen Beziehungen zwischen Wörtern erfassen können.
Unser Embedding Modell haben wir von HuggingFace und beziehen es über LangChain. Da wir fast ausschließlich in deutscher Sprache mit dem Modell kommunizieren, war es wichtig, dass es diese Sprache auch unterstützt. Eine weitere Möglichkeit, Modelle von HuggingFace zu verwenden, bietet das von HuggingFacebereitgestellte Python-Framework Sentence Transformers. Hier wird zudem ein Leaderboard (Bestenliste) mit allen Embedding-Modellen im Vergleich zur Verfügung gestellt. Das Leaderboard stellt hier eine tabellarische Übersicht dar, in der die verschiedene Modelle anhand spezifischer Eigenschaften bewertet werden.
Eine alternative kostenpflichtige Möglichkeit ist die Verwendung eines Embedding-Modells von OpenAI, welches ebenfalls über LangChain genutzt werden kann.
Welcher Abschnitt meiner Dokumente ist relevant? – Die Vektordatenbank und der Retriever
Alle vom Embedding-Modell generierten Vektoren – die Embeddings der Tokens – werden in aggregierter Form in einer Vektordatenbank gespeichert. Ein solcher aggregierter Vektor entspricht beispielsweise einem Satz oder einem Absatz. Wir verwenden FAISS als Vektordatenbank, andere bekannte Optionen sind beispielsweise Chroma oder Pinecone. Die Frage, welche der Benutzer an das RAG-System stellt, wird von dem gleichen Tokenizer und Embedding-Modell verarbeitet und somit ebenfalls in einen Vektor umgewandelt. Anschließend werden in der Vektordatenbank Vektoren gesucht, die dem Frage-Vektor ähnlich sind. Diese Suche basiert auf der Berechnung der euklidischen Distanz (similarity search). Die Vektordatenbank fungiert dabei als Retrieval-System.
Worin besteht die Aufgabe? – Die Anfrage und der Prompt
Damit das LLM eine konkrete Antwort liefern kann, muss man ihm natürlich Input liefern. Der Prompt – eine Art Befehl oder Anweisung – dient dazu, mit dem Large Language Modell zu kommunizieren. Zudem bietet er die Möglichkeit, dass Verhalten eines Sprachmodells zu steuern. Prompts müssen klar und präzise formuliert werden. Teil des Prompts von RAG-Systemen ist der Kontext aus der Vektor-Datenbank.
Ein vereinfachter Prompt an unseren Chatbot enthält im wesentlichen folgende Kernbestandteile:
| “Du bist ein Datenschutz- und Datensicherheitsexperte” | Rollenzuweisung |
| “Beantworte die gestellte Frage basierend auf dem dir übergebenen Kontext” | Aufgabendefinition |
| “Antworte mit maximal 10 vollständigen Sätzen.” | Zusätzliche Anweisungen – falls erwünscht oder notwendig |
| “Kontext: {kontext} Frage: {frage}” | Übergabe von (variablen) Informationen |
Endlich eine Antwort – Das Large Language Modell
Das LLM generiert den finalen Output unter Berücksichtigung der Anweisungen, die ihm mithilfe von Prompts übergeben werden. Bevor sich das Large Language Modell an die Textverarbeitung macht, wird auch hier jeglicher Text vorverarbeitet:
- Der gesamte Input an das LLM wird in Token aufgeteilt
- Jedes Token bekommt eine Token-ID zugewiesen, die vom LLM verarbeitet werden kann
Verschiedene LLMs übernehmen in unserer RAG-Pipeline die Rolle des „Datenschutz- und Datensicherheitsexperten“. Wir testen neben Modellen der HuggingFace Plattform, die frei zur Verfügung gestellt werden, auch GPT-Modelle von OpenAI. Die Eingliederung erfolgt mithilfe von LangChain. Eine relevante Stellschraube findet sich in dem Modell-Parameter “Temperature”. Niedrige Werte sprechen für ein faktenbasiertes Verhalten des Sprachmodells, während höherer Werte auf kreative Antworten ausgelegt sind. Dementsprechend bieten sich für RAG-Systeme niedrige Werte an.
Das Zusammenspiel aller Komponenten – Die Chain
Da nun alle Komponenten implementiert sind, muss die Pipeline natürlich noch als Ganzes zusammengefügt werden. Entsprechend des Namens verkettet die LangChain-Bibliothek die genannten Schritte zur Sprachverarbeitung.
Zu den elementaren Komponenten der Sprachverarbeitung – dem Generation-Prozess – gehören:
- Die Frage zusammen mit den ähnlichsten Abschnitten aus den Dokumenten, die bei dem Retrieval-Prozess gefunden wurden
- Der Prompt
- Das Large Language Modell

Funktioniert die Pipeline? – RAG-Evaluierung
Das Framework RAGAS bietet Evaluierungsmetriken für eine RAG-Pipeline. Ein Large Language Modell ist hier für die Bewertung verantwortlich (LLM-as-a-Judge). Das RAG-System lässt sich in zwei Prozesse unterteilen. Für beide Teile gibt es spezielle Metriken:
| Retrieval | Generation |
| Context precision – Werden die relevantesten Abschnitte auch als am relevantesten erkannt? | Faithfulness – Kann die Antwort des LLMs aus dem Kontext abgeleitet werden und ist somit glaubwürdig? |
| Context recall – Wie viel der richtigen Antwort (ground truth) erscheint in dem abgerufenen Kontext? | Answer relevancy – Ist die Antwort des LLMs relevant für die gestellte Frage? |
Für die Evaluierung nutzen wir die vier oben genannten Metriken. Zur leichteren Bewertung der beiden Prozesse fassen wird die Metriken beider Schritte zu jeweils einer Metrik zusammen.
- Retrieval-Metrik: Harmonisches Mittel aus Context precision und Context recall (angelehnt an den F1-Score)
- Generation-Metrik: Arithmetischer Mittelwert aus Faithfulness und Answer relevancy
Zusätzlich erfordert eine automatisierte Evaluation sorgfältig erstellte Testfragen und -antworten. Es empfiehlt sich, zukünftige NutzerInnen zur Erstellung der Fragen und FachexpertInnen zur Formulierung der Antworten einzubeziehen. Abhängig von der Komplexität und Vielfalt der Input-Daten sollte die Anzahl von Fragen und Antworten ausgewählt werden, idealerweise meist im zweistelligen Bereich.
Für die Evaluierung und den Vergleich verschiedener RAG-Pipelines können Experimente mit unterschiedlichen Kombinationen und Parametern durchgeführt werden, um die optimale Variante des RAG-Systems zu ermitteln. Dabei können verschiedene Vektordatenbanken, unterschiedliche Chunk-Größen und verschiedene Sprachmodelle getestet werden. Es gibt keine universell beste Kombination – jede Datengrundlage erfordert eine empirische Ermittlung des bestmöglichen RAG-Systems durch gezielte Experimente.

Sprechen Sie uns gerne an, wenn auch Sie von den individuellen Einsatzmöglichkeiten der Large Language Modelle profitieren wollen. Wir unterstützen Sie dabei, RAG auf optimale Art und Weise umzusetzen.
Mehr über die möglichen Anwendungsfälle für den RAG-Ansatz im Unternehmen erfahren Sie hier.
RAG in der Praxis - mit eoda

Beratung & Umsetzung: Wir entwickeln Ihre individuelle RAG-Lösung
Von der Konzeption über Datenmanagement und -anbindung bis hin zur Implementierung und dem sicheren Betrieb: Wir entwickeln Ihre GenAI-Lösung auf Basis des RAG-Ansatzes.

Blog: RAG - 5 Anwendungsfälle für die Verbindung aus GenAI und Unternehmenswissen
Kundensupport, Wissensmanagement und Co.: Wir stellen Ihnen fünf Anwendungsfälle für den Einsatz von RAG im Unternehmen vor.

Case Study: Mit generativer KI das Wissensmanagement optimieren
Erfahren Sie, wie wir mit einer RAG-Lösung im Wissensmanagement die Produktivität eines mittelständischen Maschinenbauers steigern konnten.
Lösung: Noch schnellerer Einstieg, dank bestehender Lösung Guinan
Entdecken Sie mit unserer Lösung Guinan, welche Vorteile durch die Kombination aus vorgefertigten Sprachmodellen und Ihrem domänenspezifischen Wissen entstehen können - ohne eine eigene Lösung bei sich zu implementieren.