Nach dem vielversprechenden Start in die useR! Konferenz 2017 am Mittwoch, konnte auch der Donnerstag mit einem abwechslungsreichen Programm für die 1.200 Teilnehmer in Brüssel aufwarten.

Show Me Your Model
Przemyslaw Biecek hat die Talks des zweiten Tages mit der Aufforderung „Show Me Your Model“ eingeleitet. Sein Vortrag hat sich der Frage gewidmet, wieso es so wichtig ist Modelle zu visualisieren.
Die beiden Hauptgründe für Biecek:
- Understanding
- Early Warnings
Konkret hat Biecek die beiden R-Pakete ggfortify und ggRandomForests thematisiert. Gerade komplizierte Modelle erfordern einfachere Zugänge um zu verstehen, was genau passiert. So lassen sich Modelle besser vergleichen, die Modellgüte ermitteln und Variablenwichtigkeiten einschätzen. Es gilt, sich nicht nur auf statistische Kennzahlen zu verlassen, sondern diese auch visuell zu überprüfen.
Can you keep a secret?
Diese Frage stellte Andrie de Vries von Microsoft. In seinem anschaulichen Vortrag hat er das R-Paket „secret“ vorgestellt. „secret“ erlaubt es Zugangsdaten zu Datenbanken, Cloud-Diensten oder anderen Services mit eingeschränktem Zugang verschlüsselt abzulegen. Dabei wird das Public-/ Private Key-Prinzip verwendet. Wenn ein größeres Entwicklerteam die Zugänge benötigt, werden diese mit allen Public-Keys verschlüsselt. Jedes Teammitglied kann dann jeweils mit seinem Private-Key die Zugangsdaten entschlüsseln. Das „secret“ Paket hilft dabei, das Procedere flüssig in den R-Code zu integrieren.
Mit „jamovi“ die Popularität von R weiter steigern
Der Vortrag von Jonathon Love hat sich einem großen Ziel verschrieben: R einer noch breiteren Nutzergruppe verfügbar machen. Für viele ist eine Skriptsprache wie R abschreckend. Mit dem R-Package „jmv“ wird der Versuch unternommen, von einem Tabellenkalkulationsansatz ähnlich wie Excel hin zum Skripten zu kommen.
eoda Data Scientist Florian Löwenstein schätzt diesen Ansatz als sehr vielversprechend ein, um R einer breiteren Masse wie beispielsweise SPSS-Nutzern zur Verfügung zu stellen. Ein menübasiertes R, ähnlich zu SPSS, und die ebenfalls aus SPSS bekannte Option des Syntax-Modus sind zusätzliche Anreize für den Einsatz von R.
Die Standardanalysen sind alle integriert und auch die Erweiterung um weitere Analysen stellt sich einfach dar. jamovi hat großes Potenzial die Popularität von R weiter zu steigern, die Zukunft wird zeigen, ob es die Lösung ist um Menschen für R zu begeistern, die bislang von Skriptsprachen abgeschreckt waren.
R im Datenjournalismus
Timo Grossenbacher, Datenjournalist beim Schweizer Radio und Fernsehen (SRF), hat in seinem Vortrag die zunehmende Popularität von R im Bereich des Journalismus thematisiert, Stärken der Programmiersprache und vorhandene Hürden aufgezeigt. Grossenbacher erklärt wie er und sein Team für ihre Reportagen auf R setzen und wie vor allem das tidyverse durch seine Zugänglichkeit für „Nicht-Programmierer“, die Verbreitung von R in ihrer Profession fördert.
Ein spannendes Thema und sicherlich eines der interessantesten Einsatzgebiete der Data-Science-Sprache. Viele Informationen und praktische Tipps für den Datenjournalismus mit R gibt es hier. Für Interessierte: R im Datenjournalismus ist auch eines der Themen auf den diesjährigen [R] Kenntnis-Tagen Anfang November in Kassel.
FFTrees für schnelle Entscheidungen
Nathaniel Phillips hat in seinem Vortrag „FFTrees: An R package to create, visualise and use fast and frugal decision trees“ ein für viele Datenanalysten sehr bekanntes Szenario geschildert: Begrenzte Zeit, begrenzte Informationen und die Anforderung gute Entscheidungen auf Basis von „noisy data“ zu treffen. Das R-Paket „FFTrees“ soll den Data Scientist in diesen Situationen unterstützen. Es handelt sich dabei um Entscheidungsbäume bei denen sich jeder Knoten nur einmal aufspaltet und sich mindestens einer der beiden Zweige als „Exit“ definiert. Zudem zeichnen sich diese Decision Trees durch eine sehr geringe Tiefe von maximal drei Knoten aus. Optimal also für Situationen in denen schnelle Entscheidungen gefordert sind – beispielsweise in der Medizin: Soll ein Patient, der mit Verdacht auf einen Herzinfarkt eingeliefert wird, auf die Intensivstation oder eine normale Station eingeliefert werden? Mit nur drei Fragen konnte eine Zuordnung mit hoher Zuverlässigkeit getroffen werden
Da die Bäume sehr einfach anzuwenden und leicht nachvollziehbar sind, ist „FFTrees“ sehr gut geeignet für praxisnahe Anwendungen und auch für Laien gut verständlich.
Entwicklungen aus dem Bereich Machine Learning
Insgesamt sehr interessant waren die Sessions zum Machine Learning. Besonders hervorzuheben sind dabei folgende Themen:
- Deep Learning mit R und MXNet: Es wurde gezeigt, wie man tiefe Convolutional Neural Networks, die sonst zur Bildanalyse verwendet werden, auch für Textanalysen verwenden kann. Im konkreten Beispiel hat der Speaker Angus Taylor anhand eines Textes einer Produkt-Review bestimmt, welcher Produktkategorie der Artikel zugeordnet ist. Eine Einführung dazu gibt es hier.
- Das Paket „ReinforcementLearning“: Dieses implementiert Verfahren aus dem gleichnamigen Gebiet des Machine Learning. Dabei geht es vereinfacht darum, dass ein Algorithmus mittels Trial-and-Error lernt. Trifft der Algorithmus die richtige Entscheidung wird er „belohnt“, trifft er die falsche Entscheidung wird er „bestraft“. Populärer Use Case: Ein Computer lernt Atari-Spiele.
Keynote zum Thema Parallel Computation in R
Parallelisierung in seiner charmantesten Form. Ein sehr sehenswerter Vortrag von Norman Matloff, in dem er dem Publikum klar gemacht hat, dass das Thema Parallelisierung kein Selbstläufer ist und es sehr viel IT-Expertenwissen benötigt. Erst dann ist eine wirklich effiziente Umsetzung möglich.

Beeindruckende Performance Verbesserungen mit „Renjin“
Ein Projekt, welches auch bei eoda schon seit längerer Zeit mit Interesse verfolgt wird ist der alternative, auf Java setzende R-Interpreter Renjin von BeDataDriven. Dieser soll Just-in-Time-Compilation ermöglichen. Da der vollwertige R-Interpreter noch etwas auf sich warten lässt, stellte Alexander Bertram von BeDataDriven das Package „Renjin“ vor. Dieses stellt eine Übergangslösung dar, bietet aber schon für einige Funktionen Just in Time Compilation mit beeindruckenden Performance Verbesserungen.
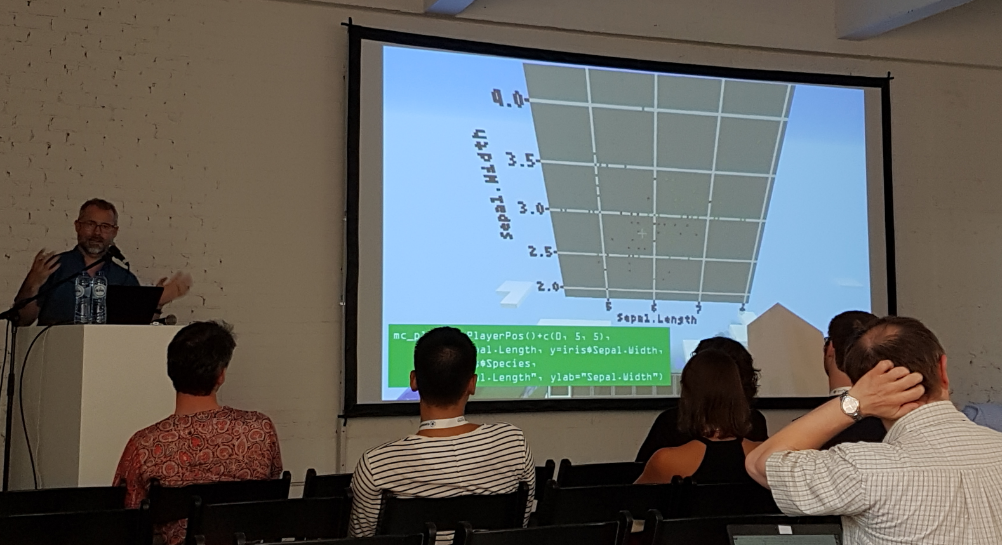
Spielerisch R lernen
„R in Minecraft“ war der Titel des Lightning Talks von David Smith. Die Verknüpfung der Programmiersprache mit dem berühmten Open-World-Game verfolgt das Ziel Kindern spielerisch Elemente aus R beizubringen und ihnen einen Einstieg in das Thema Data Science zu geben. Dazu wurden einige R-Befehle in Minecraft implementiert. So werden plots beispielweise mit Blöcken dargestellt. R ermöglicht es dem Spieler über das Wasser zu laufen – die Wasser-Blöcke werden zu Eis, wenn der Avatar darüber läuft. Das Projekt ist während der ROpenSci Unconference entstanden. Das dazugehörige R-Paket heißt „miner“. Auch begleitende Lektüre zum Thema ist vorhanden.
Traditionell einer der Höhepunkte einer useR! Konferenz ist das große Conference Dinner. Auch dieses Mal war es auf dem beeindruckenden Brüsseler EXPO-Gelände bei belgischem Essen, einer Bierverkostung und kurzweiliger Comedy eine sehr gelunge Veranstaltung der internationalen R-Community und ein würdiger Abschluss für einen ereignisreichen Konferenztag.
Hier entlang.
