In diesem Blogbeitrag wird anhand eines frei zugänglichen LKW-Datensatzes ein Predicitve Maintenance Use Case geschaffen, dessen Ziel es ist, Fehler im Luftdrucksystem der LKW vorherzusagen. Dieser soll dazu dienen, Vorgehensweisen und Modellierungen im Bezug auf Problemstellungen in der Automobilbranche zu erklären und sich im Allgemeinen der Lösung von Klassifikationsproblemen widmen. Durch die Analyse konnten die Instandhaltungskosten im optimalsten Fall um 95 Prozent reduziert werden. Das dazugehörige Dashboard begleitet den Analyse-Prozess.
Auf der IDA 2016 (Symposium über intelligente Datenanalyse) stellte die Firma Scania ihre Problematik als Industriechallenge zur freien Verfügung für alle Datenwissenschaftler, Statistiker, Hobbyprogrammierer, etc. Vorhergesagt werden sollte ein Fehler im Luftdrucksystem der firmeneigenen Schwertransporter. Ausgestattet mit einem Preisgeld von 500$ für die beiden besten Modelle ging das Problem an die Öffentlichkeit. Im Folgenden wollen auch wir uns der Herausforderung stellen und nach ausgiebiger Datenanalyse unser eigenes Modell samt Optimierung vorstellen.
Problematik – Fehlerarten & Kosten
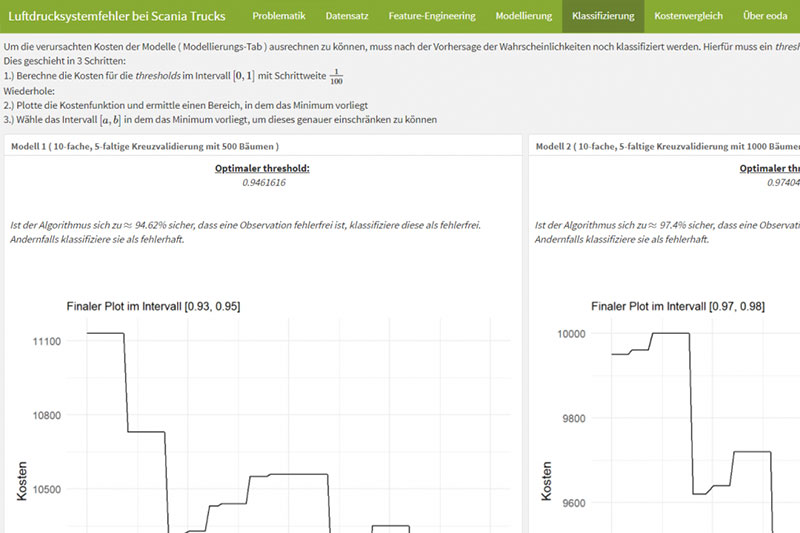
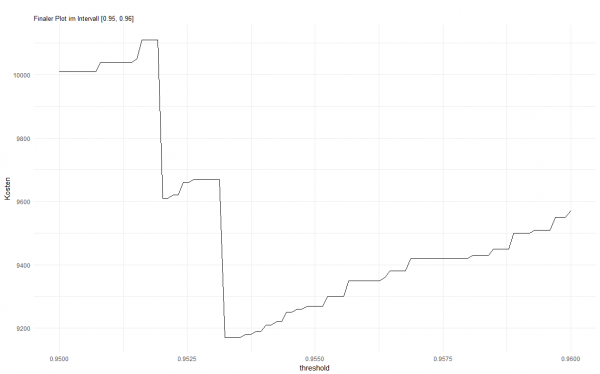
Das Problem ist simpel: Einige LKW weisen einen Fehler im Luftdrucksystem auf und deren Fehlklassifizierung bringt gewisse Kosten mit sich. Dabei wird zwischen zwei Fehlerarten unterschieden. Entweder ein fehlerfreier LKW wird zur Überprüfung in die Werkstatt geschickt (Fehler 1. Art) oder ein fehlerhafter LKW wird als fehlerfrei eingestuft und auf Tour geschickt (Fehler 2. Art). Der Fehler 2. Art wird deutlich schwerer gewichtet (Kostenfaktor: 500), als der Fehler 1. Art (Kostenfaktor: 10), da fehlerhafte Schwertransporter möglicherweise auf der Strecke liegenbleiben und so immense logistische Kosten verursachen sowie geplante Lieferzeiten in Gefahr bringen können.
Datensatzanalyse – Voraussetzungen & Stolpersteine
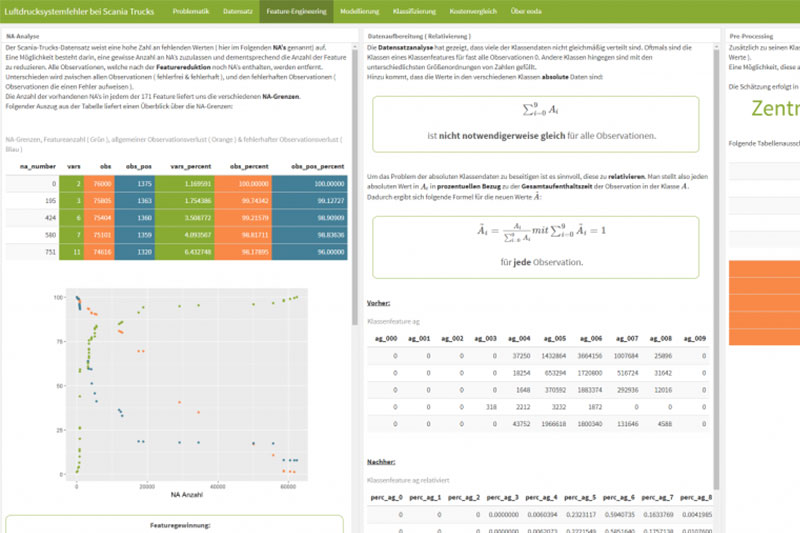
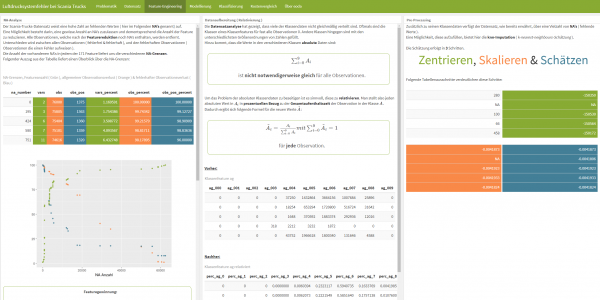
Ein erster Blick auf den mitgelieferten Beschreibungstext verrät, dass es sich hierbei keinesfalls um ein künstlich optimiertes Problem handelt, d.h. die Daten sind nicht per Hand verändert wurden, um die Modellierung einfacher zu gestalten. Wie in anderen realen Problemstellungen ist der aus 76.000 Observationen bestehende Datensatz lückenhaft und weist zusätzlich ein sehr ungleiches Verhältnis (ca. 1:55) von fehlerhaften zu fehlerfreien LKW auf. Der Datensatz, welcher 60.000 zu 16.000 in Trainings- bzw. Testdaten aufgeteilt ist, besitzt 171 erhobene Testmerkmale (Feature), welche aus Datenschutzgründen anonymisiert sind. Einige dieser Feature liegen als Klassenfeature vor, d.h. ein Feature ist in 10 Klassen unterteilt, wobei der eingetragene Wert die Aufenthaltszeit in besagter Klasse wiederspiegelt. Ein Beispiel: Temperatur des Motors von 0° – 100° als Klassenfeature. Wenn eine Observation einen Wert von 250 in der Klasse 5 des Features aufweist, bedeutet das, dass der Motor des LKW sich beispielsweise 250 Sekunden im Bereich von 40° – 50° aufgehalten hat.
Das Online-Dashboard zur Analyse finden Sie im Fazit
Datenaufbereitung – Relativierung
Betrachtet man das oben gegebene Beispiel, so wird ein Problem deutlich. Wenn man die Klassenfeature testweise über einen LKW aufsummiert, stellt man fest, dass es sich bei den eingetragenen Werten um absolute Werte handelt, die Summen sind also in der Regel unterschiedlich. Schwierig wird es dann, wenn ein LKW der viel gefahren ist einen sehr hohen Wert in der Temperaturklasse 5 aufweist, ein LKW der sehr wenig gefahren ist aber nur einen sehr niedrigen Wert – obwohl vielleicht beide, bezogen auf ihre Fahrzeit, gleich viel Zeit in dieser Klasse verbracht haben. Beide Werte werden trotzdem bei der Modellierung im selben Feature betrachtet. Es scheint also sinnvoll, diese zunächst zu relativieren, d.h. sie durch ihren prozentualen Anteil bezogen auf die Gesamtaufenthaltszeit zu ersetzen.
Datenaufbereitung – Pre-Processing
Nach der Relativierung gilt es, die fehlenden Werte im Datensatz näher zu betrachten. Eine Möglichkeit besteht darin, gewisse Grenzen für die Anzahl fehlender Werte festzulegen und demnach Feature sowie Observationen aus dem Datensatz zu entfernen. Da aber zu viele Informationen verloren gehen würden, sollten die fehlenden Werte aufgefüllt werden. Eine sehr effektive Möglichkeit hierfür bietet die k-nearest-neighbours-Schätzung. Hierbei wird der Datensatz zunächst zentriert und skaliert, danach werden die fehlenden Werte anhand der umliegenden Werte geschätzt und in den Datensatz eingefügt.
Modellierung – Modellauswahl & Performance
Bei der Modellauswahl entscheiden wir uns für das Random-Forest-Modell (RF-Modell) und versuchen dieses weitestgehend zu optimieren. Das RF-Modell bietet eine stabile Problemlösung für Klassifikationsprobleme und liefert mit zugehöriger Kreuzvalidierung durchgehend gute Ergebnisse.
In unserem Modell hat sich als Splitparameter mtry = 13 gegen mtry = 10, mtry = 17 und mtry = 20 durchgesetzt. Außerdem deklariert das Modell den gini-Index als splitrule. Die splitrule (Entscheidungsregel) gibt an, nach welchem statistischen Maß die Entscheidung über das aussagekräftigste Feature getroffen werden soll. Der gini-Index misst hierbei die Aussagekraft der Verteilung der Variable.
Variiert wird über die Anzahl der Bäume (500, 1000 und 2500), wobei das Modell mit 2500 Bäumen das beste Ergebnis liefert. Mit diesem Modell ist es gelungen, die Kosten auf 9.170 $ zu reduzieren, das entspricht ca. 0,57 $ pro LKW. Bei der Klassifizierung verursacht der Algorithmus dabei 467 Fehler 1. Art und 9 Fehler 2. Art. Im Allgemeinen liefern aber alle Variationen von mtry’s und Bäumen gute Ergebnisse, die sich im Kostenbereich sehr nah beieinander befinden. Im Vergleich dazu stehen verschiedene Kostenmodelle ohne Vorhersagemodell. Schickt man beispielsweise jeden LKW in die Werkstatt, so entstehen Kosten von 156.250 $. Schickt man keinen in die Werkstatt, so können Kosten von 187.500 $ entstehen.
Fazit
Das Scania-Trucks-Problem schafft einen interessanten Use Case. Es wird deutlich, wie Firmen sich durch intelligente Datenanalyse viel Zeit, Arbeit und Geld sparen können. Das Pre-Processing sowie die Datensatzanalyse spielen dabei genau so eine zentrale Rolle wie die Modellierung selbst.
Einen Überblick über die durchgeführten Analysen und viele weitere Zusatzinfos finden Sie im dazugehörigen Dashboard. Den Code und weiteres Material finden Sie hier. Im zweiten Teil des Artikels erklären wir nächste Woche, wie das zur Analyse gehörende Dashboard programmiert wurde. Wenn Sie Fragen oder andere Lösungswege gefunden haben, schreiben Sie einen Kommentar! Wir antworten gerne.