
Retrieval Augmented Generation (RAG)
Wie Sie große Sprachmodelle intern sicher nutzen können
Künstliche Intelligenz (KI) – insbesondere Large Language Modelle (LLMs) – haben in den letzten Jahren enorme Fortschritte gemacht. Textgeneration, Textübersetzung, das Schreiben von kreativen Inhalten oder auch das Beantworten von individuellen Fragen sind nur einige Möglichkeiten, die die Modelle in ihrer Anwendung bereits bieten. Mit dem innovativen RAG-Ansatz können LLMs noch besser und vor allem sicherer werden.

Retrieval Augmented Generation (RAG): Wie Sie große Sprachmodelle intern sicher nutzen können
Wie Sie große Sprachmodelle intern sicher nutzen können
Künstliche Intelligenz (KI) – insbesondere Generative KI – haben in den letzten Jahren enorme Fortschritte gemacht. Textgeneration, Textübersetzung, das Schreiben von kreativen Inhalten oder auch das Beantworten von individuellen Fragen sind nur einige Möglichkeiten, die die Modelle in ihrer Anwendung bereits bieten.
Vermutlich ist Ihnen bereits der Einsatz von KI auf Kommunikationsebene aufgefallen – sei es im Kundensupport, bei virtuellen Assistenten, im Rahmen von Marktforschung oder für personalisierte Empfehlungen im Online-Handel. Möglicherweise nutzen Sie auch selbst Chatbots.
Doch wie funktionieren große KI-Sprachmodelle? Wir geben einen Einblick.
Die großen generativen KI-Sprachmodelle werden mit einer Unmenge an Text trainiert, um so verständliche und dem Sachverhalt entsprechende Antworten auf individuelle Fragen zu liefern. LLMs haben jedoch auch einige Einschränkungen. Sie können manchmal ungenaue oder irreführende Informationen generieren. Dies ist der Fall, wenn sie mit Themen umgehen sollen, die nicht Teil ihrer Trainingsdaten waren. Man spricht dann vom sogenannten „Halluzinieren“. Zudem ist das reine Training der Modelle langwierig und aufwendig, sodass die Entwicklung eines eigenen Sprachmodells unrealistisch ist. Um eine kontinuierliche Aktualität zu gewährleisten, müsste man die Modelle ständig neu trainieren. Insbesondere bei Domänen, in welchen sich die Wissensbasis ständig ändert oder nicht öffentlich zur Verfügung steht, stellt dies eine große Herausforderung dar. Sollen die Sprachmodelle für interne Zwecke eingesetzt werden, besteht die Gefahr, dass interne Daten auch für das Training des LLMs eingesetzt werden.
Mit dem innovativen Ansatz der Retrieval Augmented Generation (RAG) können die bisherigen Einschränkung überwunden und eine effiziente sowie präzise Bereitstellung von fehlenden Informationen ermöglicht werden. Durch die Integration von RAG können Unternehmen ihr internes Wissensmanagement erheblich verbessern. Mitarbeitende erhalten die Möglichkeit, relevante Inhalte schneller und einfacher zu finden, einschließlich nicht frei zugänglicher interner Daten, die nun ebenfalls für Interaktionen mit einem Sprachmodell genutzt werden können.
Was ist Retrieval Augmented Generation?
RAG nutzt die Fähigkeiten, die ein LLM während seines Trainings erworben hat und kombiniert diese mit domänenspezifischem Wissen. Zusätzlich zu den ursprünglichen Trainingsdaten versorgt man das Modell mit einer externen Wissensdatenbank, um so die Möglichkeit zu haben, das Modell für konkrete Themen zu optimieren. Beispiele für externe Daten sind interne Wikis, Produktdatenblätter oder andere Dokumente. Meistens ist RAG im Rahmen eines Question-Answer-Formats wiederzufinden.
Wie funktioniert Retrieval Augmented Generation?
Im Folgenden zeigen wir das Konzept hinter RAG an einem Q&A-Anwendungsfall auf.
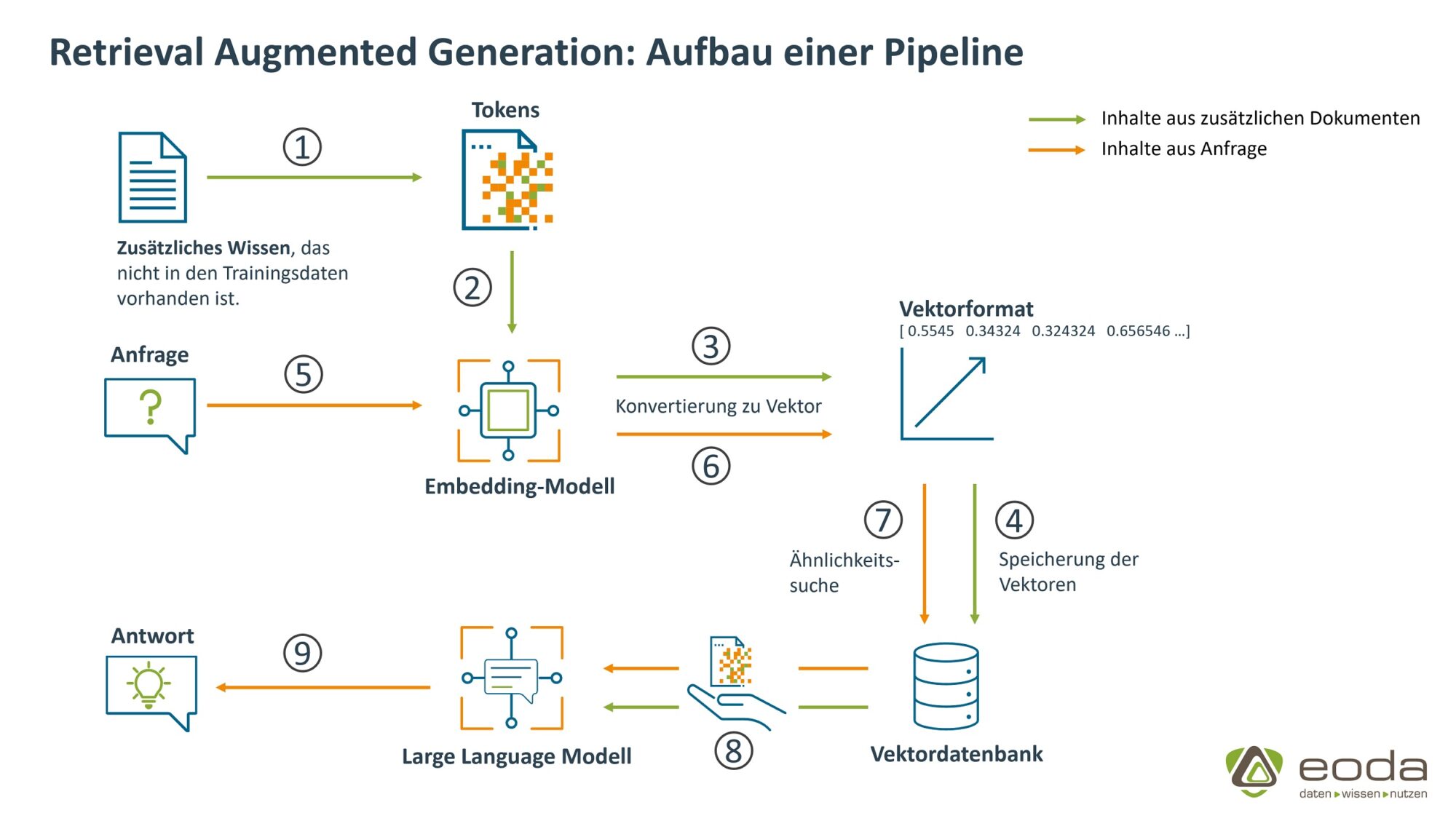
Schritt 1 & 2: Vorbereitung der Unterlagen für die externen Wissensdatenbank
Unsere externe Datenquelle bildet in einem von uns umgesetzten Beispiel die firmeninternen Datenschutz- und Datensicherheitsunterlagen. Mitarbeitende müssen somit bei Fragen zum Verhalten in besonderen Datenschutzfällen nicht in den Unterlagen blättern, sondern haben die Möglichkeit einen internen Chatbot zu fragen. Die Unterlagen müssen zunächst in sogenannte Tokens unterteilt werden.
Tokens bzw. Tokenisierung:
Tokens beziehungsweise die Tokenisierung beschreibt in diesem Zusammenhang die Zerlegung von Dokumenten in kleinere Einheiten. Neben der Möglichkeit, selbst die Anzahl an Zeichen eines Tokens zu bestimmen, kann sich die Größe auch auf ein Subwort, ein Wort oder einen ganzen Satz beziehen.
Schritt 3 & 4: Aufbau der externen Wissensdatenbank
Da ein Large Language Modell – anders als sein Name es vermuten lässt – nicht mit Text umgehen kann, müssen die Tokens nun in ein numerisches Format umgewandelt werden. Verantwortlich dafür ist das Embedding-Modell, welches aus den Tokens Vektoren generiert und in einer Vektordatenbank speichert.
Embedding-Modell
Das Embedding-Modell überführt Textdaten in hochdimensionale numerische Vektoren. Vektoren sind mathematische Darstellungen von Merkmalen oder Attributen. Jeder Vektor hat eine bestimmte Anzahl von Dimensionen, die je nach Komplexität und Granularität variieren kann. Diese Vektoren repräsentieren den semantischen Inhalt des Textes, wobei ähnliche Texte ähnliche Vektoren haben. Für alle Text-zu-Vektor-Umwandlungsschritte wird ein einheitliches Embedding-Modell verwendet, da ansonsten die oben genannte Funktion der Kontextrepräsentation verloren geht.
Schritt 5 & 6: Anfrage an die Wissensdatenbank
Sobald die firmeninternen Datenschutz- und Datensicherheitsunterlagen in der Vektordatenbank gespeichert sind, können Anfragen an die Wissensdatenbank gestellt werden. Die gestellte Frage wird mithilfe des gleichen Embedding-Modells, das auch bei der Erstellung der Wissensdatenbank verwendet wurde, in einen numerischen Vektor umgewandelt. Dieser Vektor repräsentiert die semantische Bedeutung der Frage.
Retrieval-Prozess
Schritt 7: Ähnlichkeitssuche in der Wissensdatenbank
Der erzeugte Fragevektor wird genutzt, um in der Vektordatenbank nach Vektoren zu suchen, die semantisch ähnlich sind.
Large Language Model
Large Language Modelle (LLM) sind neuronale Netze, welche speziell für die Verarbeitung und Erzeugung von natürlicher Sprache entwickelt wurden. Sie lernen Muster und Strukturen in großen Textdatensätzen zu erkennen, um so Texte zu verstehen, zu generieren oder in verschiedener Art und Weise mit natürlicher Sprache zu interagieren
Generation-Prozess
Schritt 8: Umwandlung in ursprüngliches Textformat & Kontextübergabe an ein LLM
Die gefundenen Vektoren werden in ihre ursprüngliche Textformate zurück gewandelt – sie entsprechen nun den Textabschnitten aus den Datenschutz- und Datensicherheitsunterlagen. Die Anfrage an das System wird zusammen mit den ähnlichen Textabschnitten der Datenschutz- und Datensicherheitsunterlagen an ein Large Language Modell übergeben.
Schritt 9: Finale Antwortgenerierung des LLMs
Mithilfe der zusätzlichen Informationen generiert das LLM eine Antwort die spezifisch auf unseren Q&A-Anwendungsfall zugeschnitten ist und die von uns bereitgestellten Datenschutz- und Datensicherheitsunterlagen als Basis verwendet.
Vorteile von Retrieval Augmented Generation
Aktualität:
Mithilfe von RAG können ausgewählte Informationen leichter up-to-Date gehalten werden. Ein komplettes Neutraining des LLMs ist nicht notwendig.
Erweiterter Wissensspeicher:
Es können beliebige Wissensquellen in den generativen Prozess miteinbezogen werden. So eröffnet sich auch die Möglichkeit, das LLM auf einen bestimmten Fachbereich, beispielsweise die Medizin, zu spezialisieren. Des Weiteren kann man neben dem “Was” auch das “Wie” der übergebenen Informationen bestimmen. Ist es gewünscht, so können die externen Daten in individueller Weise aufbereitet werden (bestimmte Gliederung, Schlüsselwörter, …)
Reduzierung von Halluzinationen:
LLMs haben oft die Tendenz, fiktive oder ungenaue Informationen zu generieren. RAG kann diese Neigung verringern, indem es auf verlässliche externe Quellen verweist.
Korrigieren oder Löschen von Falschinformationen:
Finden sich Falschinformationen oder sich ändernde Informationen in der zusätzlich verwendeten Wissensbasis, so können diese einfach korrigiert oder entfernt werden.
Kosteneffizienz:
Da mithilfe von RAG einfach zusätzliches Wissen in ein LLM miteinfließen kann, ist ein komplettes Neutraining eines großen Sprachmodells nicht notwendig. Dadurch können Ressourcen eingespart werden.
Flexibilität und Unabhängigkeit:
Bestandteile einer RAG-Pipeline- beispielsweise das Large Language Modell, das Embedding-Modell oder auch die Datenbank, in welcher die Vektoren gespeichert werden – können flexibel ausgetauscht werden. So kann stets auf die aktuelle Technologie zurückgegriffen werden. Außerdem trägt auch die Möglichkeit der Veränderbarkeit der externen Wissensquelle zu erhöhter Flexibilität bei. Durch die Ersetzungsmöglichkeiten entstehen zudem keine Abhängigkeiten von gewissen Bestandteilen eines RAG-Systems.
Integrierbares System:
Arbeitet man bereits mit Sprachmodellen, so lässt sich das RAG-System gut in die bisherige Pipeline einbauen.
Fazit
Insbesondere im Bereich des Wissensmanagements zeigt RAG ein enormes Potenzial. Dabei werden die Grenzen von LLMs durch die Integration von domänenspezifischem Wissen bei jeder Antwortgenerierung überwunden. So können Unternehmen RAG nutzen, um effizient auf internes Wissen zuzugreifen und Mitarbeitenden relevante Informationen bereitzustellen.
RAG zeigt insbesondere dann seine Stärken, wenn es um die Kombination von kommunikationsorientierter KI und internen Informationen geht. Dieser Ansatz stellt sicher, dass Aspekte wie Vertrauen, Genauigkeit und Erklärbarkeit berücksichtigt und adressiert werden. So kann die Nutzung von LLMs ohne Zweifel und Unsicherheiten erfolgen. Zudem ermöglicht diese Technologie eine flexible Anpassung an äußere Umstände und die kontinuierliche Berücksichtigung aktueller Entwicklungen in der KI, wie zum Beispiel neue Algorithmen, ethische Richtlinien und Datenschutzanforderungen.
Sprechen Sie uns gerne an, wenn auch Sie von den individuellen Einsatzmöglichkeiten der Large Language Modelle profitieren wollen. Wir unterstützen Sie dabei, RAG auf optimale Art und Weise umzusetzen.
Mehr über die möglichen Anwendungsfälle für den RAG-Ansatz im Unternehmen erfahren Sie hier.
RAG in der Praxis - mit eoda

Beratung & Umsetzung: Wir entwickeln Ihre individuelle RAG-Lösung
Von der Konzeption über Datenmanagement und -anbindung bis hin zur Implementierung und dem sicheren Betrieb: Wir entwickeln Ihre GenAI-Lösung auf Basis des RAG-Ansatzes.

Blog: RAG - 5 Anwendungsfälle für die Verbindung aus GenAI und Unternehmenswissen
Kundensupport, Wissensmanagement und Co.: Wir stellen Ihnen fünf Anwendungsfälle für den Einsatz von RAG im Unternehmen vor.

Blog: RAG in der Praxis: Aufbau einer RAG-Pipeline für einen Chatbot
Von der Wissensbasis bis zum LLM: Wir stellen Ihnen den Aufbau einer RAG-Pipeline Baustein für Baustein vor.

Lösung: Noch schnellerer Einstieg, dank bestehender Lösung Guinan
Entdecken Sie mit unserer Lösung Guinan, welche Vorteile durch die Kombination aus vorgefertigten Sprachmodellen und Ihrem domänenspezifischen Wissen entstehen können - ohne eine eigene Lösung bei sich zu implementieren.