
Mit Machine Learning und Python zur umfassenden Lastprognose
Die Lastprognose, also die Vorhersage des Stromverbrauchs beispielsweise eines Gebäudes oder Gebietes, ist ein wichtiger Bestandteil bei der Planung und Optimierung von Stromnetzen. Basis für zuverlässige Vorhersagen ist die Erkennung von Mustern im Verbrauchsverhalten.

Mit Machine Learning und Python zur umfassenden Lastprognose
Die Lastprognose, also die Vorhersage des Stromverbrauchs beispielsweise eines Gebäudes oder Gebietes, ist ein wichtiger Bestandteil bei der Planung und Optimierung von Stromnetzen. Basis für zuverlässige Vorhersagen ist die Erkennung von Mustern im Verbrauchsverhalten.
Je mehr Strom ein Verbraucher nutzt, desto wichtiger ist es für die Gesamtprognose seinen Verbrauch gut vorherzusagen. Einzelne Haushalte haben in der Regel einen zu geringen Verbrauch, um maßgeblichen Einfluss auf Lastentwicklungen zu haben und sind daher nicht im Fokus von Lastprognosen. Damit eine gute Vorhersage gelingt, müssen oft verschiedene Datenquellen berücksichtigt und analysiert werden.
In diesem Blogbeitrag zeigen wir Ihnen, wie wir mit Hilfe bekannter Machine Learning Modelle einen Demonstrator für Verbrauchsprognosen von realen Lastgängen erstellt haben. Der Demonstrator ist eine Beispielanwendung, die das Modelltraining zur Lastprognose und eine Benutzeroberfläche, die die Modellperformance darstellt, umfasst. Wir zeigen Ihnen daher auch, wie wir die Ergebnisse für eine einfache und schnelle Interpretation visualisiert haben. Aufrufen und ausprobieren können Sie die Oberfläche hier.
Warum Lastprognosen?
Ein wichtiger Baustein der Energiewende ist die präzise Lastprognose eines Netzes. Stromnetze stabil zu halten und Engpässen entgegenzuwirken ist angesichts von Erneuerbaren Energien eine größere Herausforderung, da die Stromproduktion hier von nicht beeinflussbaren Faktoren wie Wind und Sonne abhängt.
Die Einspeisung von Strom ins Netz, vor allem von Kraftwerken, muss daher gut geplant werden, damit das Stromnetz stabil bleibt und ausreichend Strom zur Verfügung steht. Zuverlässige Lastprognosen sind daher wichtig, um die Stromnachfrage möglichst kostengünstig bedienen zu können. Fehlt kurzfristig Strom muss dieser teuer eingekauft werden. Mit zuverlässigen Prognosen können zudem langfristigere Lieferverträge, oft auch mit besseren Konditionen abgeschlossen werden. Mit zuverlässigen Prognosemodellen kann so der Ausbau eines Netzes optimiert sowie Kosten und der Einsatz von Ressourcen reduziert werden. Auch kann damit ein zukunftssicherer und nachhaltiger Betrieb des Netzes etabliert werden.
Ein zusätzlicher Vorteil von zuverlässigen Lastprognosen: Sie können erste Hinweise zu Auffälligkeiten im gemessenen Stromverbrauch liefern. Eine hohe Abweichung von Prognose und Realität kann beispielsweise an fehlerhaften technischen Komponenten liegen. Auch andere Ursachen sind denkbar. Je früher mögliche Probleme identifiziert werden, desto besser. Eine gute Lastprognose kann somit auch eine implizite Anomalieerkennung ermöglichen.
Umsetzung der Lastprognose
Die Erstellung der Beispielanwendung haben wir in mehrere Schritte aufgeteilt:
- Datenauswahl
- Modelltraining
- Modellerklärungen (XAI)
- Visualisierung & Erstellung einer grafischen Oberfläche
Ziel der Beispielanwendung ist es, dass Nutzende die Lastprognosen einfach und schnell interpretieren und evaluieren können. Das umfasst auch den direkten Vergleich mehrerer Modelle.
Technische Rahmenbedingungen der Lastprognose
Programmiersprache: Python
Verwendete Pakete:
- Für die Datenverarbeitung: Pandas
- Für Visualisierung & Dashboard: Streamlit und Plotly
- Für das Modelltraining: Numpy, Mlflow, Scikit-Learn, Skforecast & XGBoost
Auswahl geeigneter Daten
Bei der Nutzung von Zeitreihen, wie hier die historischen Verbrauchsdaten aus jüngerer Vergangenheit, gilt erstmal der Grundsatz je mehr Daten, desto besser. Dies gilt nicht nur bei dem Zeitraum, den der Datensatz abdeckt, sondern kann in abgeschwächter Form auch über die Anzahl der Attribute gesagt werden. Attribute, auch als Merkmale oder Feature bezeichnet, sind die Informationen, die zum Modelltraining genutzt werden.
Herausforderung 1 – Datenverfügbarkeit
Die verfügbaren Daten, vor allem im Hinblick auf die Länge der Verbrauchszeitreihen und der damit korrespondierende weitere Attribute, spielen eine wesentliche Rolle bei der Modellperformance. Dazu gehört auch eine hohe Datenqualität, beispielsweise bedeuten fehlende Werte zusätzlichen Aufwand in der Datenvorverarbeitung und senken die Prognosequalität.
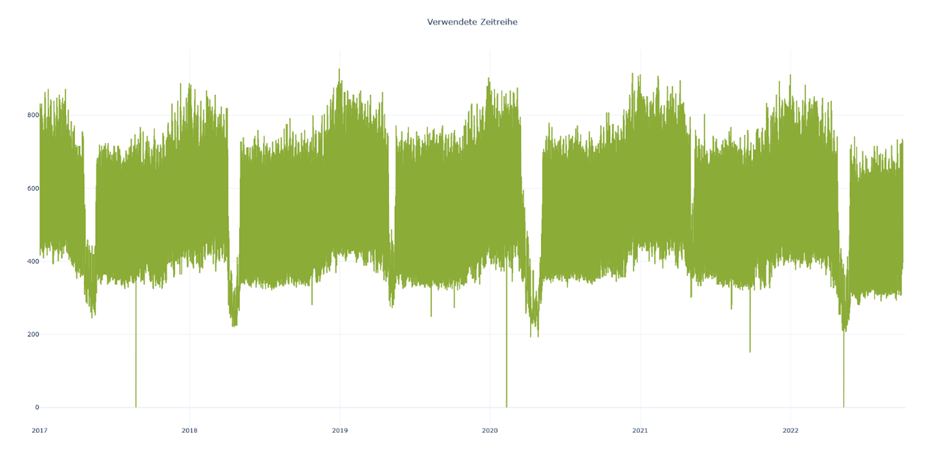
Wir nutzen exemplarisch eine reale Verbrauchszeitreihe mit einem hohen Grundverbrauch. Sie stammt aus der Praxis und umfasst Daten aus 5,5 Jahren. Mit einer zeitlichen Auflösung von 15 Minuten liegen pro Jahr ca. 17.500 gemessene Werte vor. Wie die Abbildung zeigt, hat die Zeitreihe einen sehr regelmäßigen Verlauf, enthält aber auch einige Unregelmäßigkeiten. Das ist eine gute Grundlage, um die Performance verschiedener Modelle vergleichen zu können.
Neben den Lastdaten, in diesem Zusammenhang auch historische Werte genannt, nutzen wir zusätzliche Attribute für das Modelltraining:
- Zeit aufgeteilt in Uhrzeit, Wochentag, Tag und Monat
- Lokale Feiertage
- Wetterdaten wie Wind, Sonneneinstrahlung, Temperatur und Regen
Modelltraining
Eine Vielzahl an klassischen Machine-Learning-Algorithmen ssind für die Vorhersage von Zeitreihen und daher auch Lastprognosen geeignet. Wir nutzen mit XGBoost ein Verfahren, das Entscheidungsbäume und Gradient Boosting kombiniert und damit oft eine bessere Performance erreicht als beispielsweise Random Forest. XGBoost ist in der Lage komplexe und nicht-lineare Muster zu erkennen, was es für unseren Anwendungsfall sehr geeignet macht. Außerdem ist es gut skalierbar und daher bei eoda unser bevorzugter Algorithmus in einer Vielzahl an Anwendungsfällen. Durch parallelisierte Berechnungen innerhalb eines Baumes ist das Modelltraining zudem effizient. Dies ermöglicht das lokale Training innerhalb kurzer Zeit auf einem Notebook. Server mit höherer Rechenleistung wurden in unseren Modelltrainings nicht benötigt. Bei deutlich umfangreicheren Zeitreihen kann die Nutzung eines Servers jedoch gelegentlich notwendig werden.
Für das Modelltraining nutzen wir die Python Bibliotheken Skforecast in Verbindung mit Scikit-Learn und XGBoost. Skforecast ist speziell für die Vorhersage von Zeitreihen entwickelt worden und ermöglicht es auf Grundlage von Regressionsmodellen Vorhersagen für einen zukünftigen Zeitraum zu machen. Die Regressionsmodelle können aus verschiedenen Paketen kommen, die dem Interface von Scikit-Learn entsprechen wie beispielsweise XGBoost. Nach der Datenaufbereitung und der Unterteilung in Trainings- und Validierungsdaten nutzen wir ein sogenanntes ForecasterAutoreg-Objekt aus der Skforecast Bibliothek für das Modelltraining. Um die Modellperfomance zu verbessern, führen wir eine Hyperparameteroptimierung durch. Sie erfolgt mit Hilfe einer Grid Search, bei den systematisch verschiedenen Kombinationen von vorgegebenen Parameterwerten getestet werden um das beste Modell zu finden. Außerdem nutzen wir Backtesting bei der Modelloptimierung.
Backtesting ist eine Evaluationsmethode, bei der das Modell auf historischen Daten aus dem Trainingszeitraums angewandt wird, um zu testen, wie gut die Vorhersage für den Zeitraum gewesen wäre. Das Ziel von Backtesting ist es unter anderem die Robustheit des Modells zu testen. Für die Modelloptimierung wird ein Validierungszeitraum von acht Monaten, der im Anschluss an den Trainingszeitraum liegt, genutzt. Für diesen Zeitraum sagt das trainierte Modell den Stromverbrauch vorher und die Abweichungen zum tatsächlichen Stromverbrauch werden berechnet. Damit kann auf nicht für das Training genutzten Daten die Modellperformance evaluiert werden.
Die Beispielanwendung soll jedoch nicht nur eine einzelne Lastprognose bieten, sondern auch den Vergleich zwischen verschiedenen Prognosen ermöglichen. Daher haben wir mehrere Modelle trainiert, für die wir verschiedene Kombinationen aus den aufgeführten Attributen und der Länge des Trainingszeitraums verwendet haben:
- Nur Lastgang – Zeitspanne: 1 Jahr
- Lastgang und Zeitattribute – Zeitspanne: 1 Jahr
- Lastgang, Zeitattribute, Wetterdaten – Zeitspanne: 1 Jahr
- Lastgang, Zeitattribute, Wetterdaten – Zeitspanne: 6 Monate
- Lastgang, Zeitattribute, Wetterdaten – Zeitspanne: 1 Monat
Alle von diesen aufgeführten Kombinationen wurden unabhängig voneinander trainiert.
Als weiteres Vergleichsaspekt um die Performance der XGBoost-Modelle zu evaluieren, nutzen wir einfache Baseline-Modelle. Das ist ein übliches Vorgehen beim Vergleich von Modellen. Dadurch erhält man einen besseren Eindruck von der tatsächlichen Performance der Modelle gegenüber einfachen Regellogiken. Wir haben uns dafür entschieden SNAIVE-Modelle (Seasonal-Naive) als Baselinemodelle zu verwenden. SNAIVE-Modelle sind gut geeignet für Zeitreihen mit stark saisonalem Charakter. Das sind Zeitreihen mit immer wiederkehrenden zeitabhängigen Mustern. Wenn beispielsweise die Stromverbräuche immer abends sehr hoch sind und an den meisten Tagen einem ähnlichen Verlauf folgen, kann man davon ausgehen, dass die Tageszeit eine Rolle beim Stromverbrauch spielt. SNAIVE-Modelle basieren auf der Annahme, dass die beste Vorhersage für Werte in einer solchen Zeitreihe Werte aus der Vergangenheit derselben Zeitreihe sind, die zeitlich versetzt werden, beispielsweise um genau ein Jahr oder eine Woche. Der gewählte zeitliche Versatz, hängt von den Charakteristiken in der Zeitreihe ab. Wenn der Stromverbrauch hauptsächlich von der Tageszeit abhängt, kann es beispielsweise sinnvoll sein, den Wert von vor 24 oder 48 Stunden auszuwählen. Für unsere Lastprognose nutzen wir die Werte von vor 48 Stunden und von vor 7 Tagen, da die genutzte Zeitreihe deutlich abhängig ist von der Tageszeit und leichte Muster im Wochenverlauf hat.
Herausforderung 2 – Modellperformance bei Unregelmäßigkeiten
Verbrauchszeitreihen können sehr regelmäßig in ihrem Verhalten sein, jedoch treten nicht selten auch zeitweise Abweichungen von diesem normalen Verhalten auf. Ein Beispiel dafür ist ein zeitweise geringerer Verbrauch über einen Zeitraum von wenigen Tagen. Auch unsere Zeitreihe umfasst solche Unregelmäßigkeiten, wie in der Abbildung der Zeitreihe schnell erkennbar ist. Die zuverlässige Erkennung und Berücksichtigung dieser in der Prognose ist nicht einfach zu lösen. Weitere Attribute hinzuzunehmen und den Trainingszeitraum anzupassen, kann einen positiven Effekt auf die Modellperformance haben. Herausfordernden Sequenzen können zudem hilfreich sein beim Modellvergleich.
Modellerklärbarkeit (XAI)
Erklärungen für Modellentscheidungen steigen an Bedeutung. Eine Einführung in das Thema Explainable AI (XAI) und XAI mit SHAP haben wir bereits in unserem Blog behandelt. Für die Beispielanwendung nutzen wir die Feature Importance, also die Relevanz aller Attribute für die Vorhersage des Models. Wir machen uns hier zu Nutze, dass XGBoost auf Entscheidungsbäumen basiert und nutzen den Information Gain. Er gibt an in welchem Umfang sich ein Modell verbessert, wenn ein bestimmtes Attribut, z.B. die Temperatur, im Modelltraining hinzugenommen wird. Daher gilt: Ein höherer Information Gain weist auf einen höheren Einfluss des Modellattributs auf die Vorhersage hin.
Für alle Modelle werden die Feature Importance Werte für alle verwendeten Attribute auf den optimierten Modellen berechnen. Ausnahmen sind dabei alle Modelle, die nur auf historischen Werten trainiert wurden. Hier ist die Nutzung der Feature Importance nicht notwendig, da das nur ein Attribut verwendet wurde.
Visualisierung & Dashboard
Die entwickelten Modelle und daraus gewonnen Informationen werden im Demonstrator in einer Benutzeroberfläche dargestellt. Im Detail können Sie sich die Oberfläche hier anschauen. Dabei gibt es 3 Hauptbausteine:
- Darstellung der Verbrauchszeitreihe
- Darstellung der Modellperformance mit Vergleich verschiedener Modelle
- Darstellung der wichtigsten Attribute je Modell (Feature Importance)
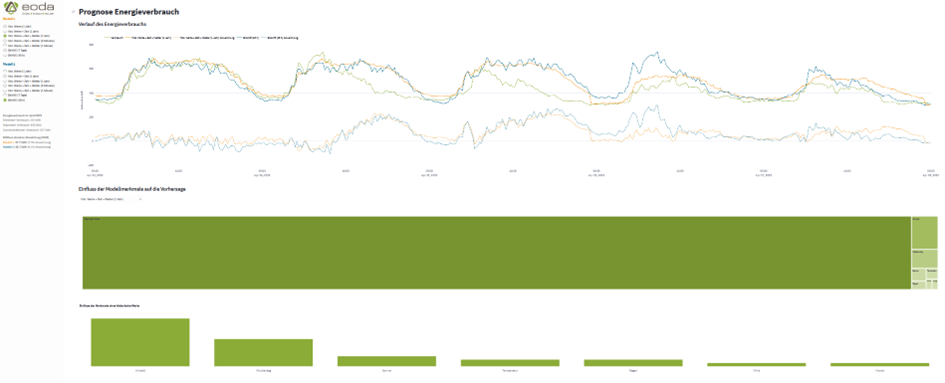
Für die Entwicklung der grafischen Oberfläche nutzen wir Streamlit und Plotly.
Streamlit ist ein umfangreiches Python-Paket, dass es ermöglicht, einfach und flexibel Benutzeroberflächen zu erstellen. Dabei bleibt die Syntax nah an Python-Code, und erfreut sich daher bei uns für die schnelle Visualisierung von Daten und Modellen sowie Proof of Concepts großer Beliebtheit. Plotly ist ein sehr bekanntes und beliebtes Paket für die Erstellung von Grafiken. Ein großer Vorteil von Plotly gegenüber Paketen wie Matplotlib ist die integrierte Interaktivität der Grafiken. Dies erlaubt eine andere Arbeitsweise mit den Grafiken, beispielsweise durch Bereitstellen von Hoverinformationen und Nutzung der Zoomfunktion, die bei langen Zeitreihen sehr hilfreich sein kann.
Herausforderung 3 – Übersichtlichkeit & Informationsreichtum
Die Darstellung muss eine gute Balance aus Übersichtlichkeit und Informationstiefe schaffen. Die Hauptaussagen sollten schnell erkennbar sein und dennoch einen Informationsgehalt bieten, der es ermöglicht sich als Nutzender tiefergehend mit den Daten und Modellen auseinanderzusetzen. Um diese Balance zu schaffen, nutzen wir interaktive Grafiken und einfache Mechanismen für die Zuordenbarkeit von zueinander gehörenden Informationen, beispielsweise über Farbwahl.
Die Abbildung der Benutzeroberfläche des Demonstrators zeigt bereits, wie wir die drei genannten Bausteine zu einer Oberfläche zusammengesetzt haben.
Für die Darstellung der Verbrauchszeitreihe und Vorhersagen haben wir einen einzelnen Monat ausgewählt. Dieser Zeitraum, der ca. 10.800 Datenpunkte umfasst, wurde auf Basis mehrerer Kriterien gewählt:
- umfasst regelmäßige und unregelmäßige Sequenzen, was die Aussagekraft des Vergleichs erhöht,
- einfach visuell zu überblicken und
- schnelle Ladezeiten.
Zusätzlich haben wir einen Zeitraum von 5 Tagen als Default eingestellt, mit dem die App geladen wird. Der Zeitraum ist so gewählt, dass er den Übergang von regelmäßigem zu unregelmäßigem Verhalten zeigt. Die Abbildung zur Darstellung der Modellperformance zeigt ebenfalls diesen Zeitraum. Der Ist-Verbrauch wird im Liniendiagramm in grün dargestellt, zusätzlich dazu wird die Modellperformance zweier anderer Modelle in blau und orange angezeigt. Die Linien mit geringerer Sättigung rund um die x-Achse zeigen zusätzlich den Fehler der beiden Modelle pro Vorhersagezeitpunkt an.
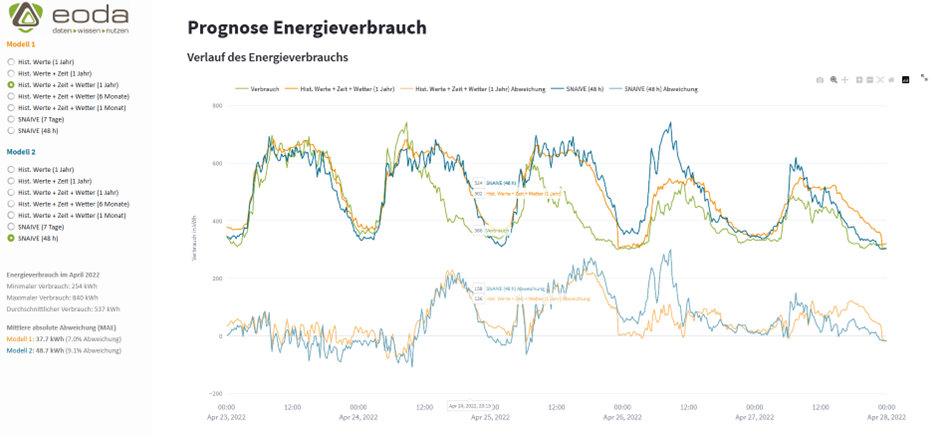
Unsere Oberfläche verfügt über eine Seitenleiste. In dieser wird der Gesamtzeitraum mit einer statistischen Übersicht über die Verbrauchswerte dargestellt. Außerdem können hier die beiden zu vergleichenden Modelle ausgewählt werden. Die Prognosequalität der ausgewählten Modelle mit Hilfe der mittleren absolute Abweichung (engl. mean average error / MAE) wird ebenfalls in der Seitenleiste angezeigt. Sie gibt über alle Datenpunkte des gesamten Monats an, um wie viele Kilowattstunde die Vorhersage durchschnittlich vom tatsächlichen Wert abweicht.
Die Abweichungen der ausgewählten Vorhersagemodelle vom tatsächlichen Wert werden auch graphisch dargestellt, damit die Modelle einfacher miteinander verglichen werden können. Wir nutzen verschiedene Farben, um Zusammengehörigkeit anzuzeigen. Jedes ausgewählte Modell hat eine andere Farbe. Sie findet sich bei der Modellauswahl, in der Metrikangabe und im Liniendiagramm wieder. Im Liniendiagramm wird die Sättigung für die Darstellung der Modellabweichungen verringert, um Vorhersagen und Fehler optisch zu gewichten.
Außerdem nutzen wir Hoverinformationen, sodass für jeden Zeitpunkt der tatsächliche Verbrauchswert, die Vorhersage und die Abweichung der Vorhersage vom tatsächlichen Verbrauch für beide Modelle angezeigt werden kann. Dies erlaubt Informationstiefe, die in der Praxis wichtig sein kann, ohne zu einer großen Unübersichtlichkeit zu führen.
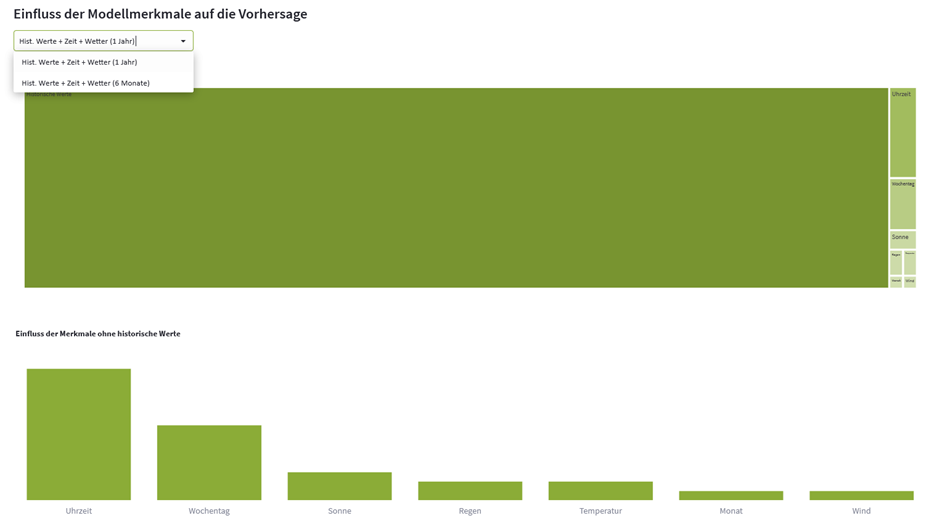
Für die Modellerklärung werden die Feature Importance Werte für eines der ausgewählten Modelle dargestellt. Das anzuzeigende Modell kann hier über ein Dropdown-Menü ausgewählt werden. Die obige Abbildung zeigt das. Basiert nur ein Modell auf Attributen außer den historischen Werten, kann nur dieses Modell ausgewählt werden. Basieren beide Modelle nur auf historischen Werten, entfällt die Darstellung komplett. Auch hiermit wollen wir die Klarheit und Übersichtlichkeit des Dashboards erhöhen, da bei Modellen, die nur ein Attribut nutzen die Feature Importance überflüssig ist.
Die Merkmalsrelevanzen werden über einen Kacheldiagramm und ein nachgelagertes Säulendiagramm dargestellt. Kacheldiagramme sind gut geeignet um die Wichtigkeit einzelner Kategorien, wie Merkmale im Modelltraining, darzustellen. Gegenüber Kreisdiagrammen haben sie den Vorteil, dass man visuell die Proportionen der Klassen besser erkennen kann. Sie haben aber den Nachteil, dass bei sehr unausgeglichenen Wichtigkeiten die kleineren Werte nur schwer visuell erkennbar sind. Viele grafische Darstellungen haben diesen Nachteil. Wir stellen daher alle Merkmale außer dem Lastgang, der bei allen Modellen deutlich das wichtigste Attribut ist, in einem separaten, nach Relevanz der Attribute sortierten, Säulendiagramm dar.
Damit ist unser Demonstrator fertig. Dank Streamlit ist ein einfaches Deployment lokal oder auf einem Server möglich. Unsere Benutzeroberfläche ist dann bereit einen Mehrwert zu liefern.
Adaption der Lastprognose auf weitere Anwendungsfälle
Das vorgestellte Vorgehen ist nicht an den konkreten Use Case gebunden und kann sehr flexibel adaptiert und erweitert werden. Für Prognoseaufgaben ist der Anpassungsaufwand gering. Aber auch Klassifikationsaufgaben, also das muster-basierte Kategorisieren von Daten, können ähnlich dargestellt werden. Die hier benannten Herausforderungen treten in ähnlicher Form in vielen unserer Projekte auf. Zwei Gedanken wollen wir Ihnen daher noch mitgeben.
- Nutzen Sie die verfügbaren Daten, von denen Sie begründet annehmen, dass sie einen relevanten Effekt auf Ihre Zielvariable haben. Das kann auch bei der Orientierung helfen, wie viel Aufwand Sie in Datenbeschaffung und -aufbereitung stecken sollten. Während beispielsweise die Anzahl der Bewohner eines Hauses einen deutlichen Einfluss auf den Stromverbrauch dieses Gebäudes haben kann, ist die genaue Adresse des Hauses oftmals irrelevant.
- Bei der Auswahl des Modells sollten Sie zunächst einfache (Benchmark-)Modelle ausprobieren. Wenn die Performance nicht zufriedenstellend ist, arbeiten Sie sich langsam hoch zu komplexeren Modellen. Oft liefern einfache Machine Learning Modelle gleichwertige Performance zu komplexeren, sind dabei aber im Hinblick auf Erklärbarkeit verständlicher und benötigen weniger Rechenressourcen.
Case Studies: Einblicke in datengestützte Erfolgsgeschichten
Case Study:
Wie gelingt die Einführung von Data Science im Unternehmen?
Die Primeo Netz AG erschließt das Potenzial von Künstlicher Intelligenz in der Energiewende – von der Vision zum Produktiveinsatz.

Case Study:
Automatisierung des Fahrplanmanagements mittels KI
In Zeiten immer volatiler werdender Stromproduktion und – nachfrage bei gleichzeitig fortschreitender Digitalisierung der Infrastrukturen kann Künstliche Intelligenz ein zentraler Baustein für das Fahrplanmanagement der Zukunft sein.

Case Study:
Digitaler Zwilling & KI in der Solarenergie
Steigerung der Wirtschaftlichkeit und Nachhaltigkeit von Photovoltaiksystemen durch den Einsatz von Data Science.
Case Study:
Leistungsprognose Photovoltaik für die Planung des Netzausbaus
Wie viel Solarenergie wird wann produziert und wo in das Netz eingespeist?
Sie möchten mehr zum Einsatz von KI in der Energiewirtschaft erfahren?
Wir freuen uns auf Ihre Anfrage.