Stammdaten- und Datenqualitätsmanagement - Treiber für KI und Data Science
Lesezeit: ca. 3 Min.
Das Stammdatenmanagement und das Datenqualitätsmanagement (auch Master Data Management oder Data Quality Management genannt) sind die Grundlage, um nachhaltige Unternehmensentscheidungen zu treffen sowie im digitalen Zeitalter wettbewerbsfähig zu bleiben. Somit können Entscheidungen aufgrund von Daten getroffen werden, anstatt lediglich auf das eigene Bauchgefühl zu hören.
Die Datenqualität sowie das Stammdatenmanagement sind Teil der Datenstrategie des Unternehmens und gelten als Treiber für Data-Science- und KI-Initiativen sowie als elementare Stütze in einer verstärkt komplexeren Datenwelt. Haben die Daten eine gute Qualität, können diese als Trainingsdaten für das Lernverfahren der KI genutzt werden.
In der Praxis wird die Datenqualität allerdings häufig vernachlässigt. Daten können fehlerhaft sein, sich widersprechen, unvollständig oder veraltet sein. Das Problem von fehlerhaften und unvollständigen Daten liegt darin, dass die unzureichende Datenqualität ausschlaggebende Auswirkungen auf das Unternehmen haben kann – von Lieferverzug bis hin zu unzufriedenen Kundinnen und Kunden.
Was sind Stammdaten?
Stammdaten sind Grundinformationen über betrieblich relevante Elemente, wie z. B.
- Kunden
- Lieferanten
- Produkte und Artikel
- Konten
- Preislisten
- Mitarbeitende
- Standorte etc.
Das Stammdatenmanagement und die Datenqualitätssicherung sind somit für jedes Unternehmen von Bedeutung. Das Stammdatenmanagement ist ein permanenter Prozess, in welchem Daten angelegt, aufbereitet, gepflegt, kontrolliert, standardisiert, synchronisiert sowie analysiert werden. Damit werden alle Informationen des Unternehmens in ein einheitliches Ganzes gebracht. Die Vorgaben für die Pflege, Verwaltung etc. können mittels Data Governance vereinheitlicht werden. StammdatenmanagerInnen (auch Data Stewards genannt) können hier behilflich sein, um auf die Umsetzung der Vorgaben zu achten. So können fehlerfreie Daten, welche sich über mehrere Systeme und Anwendungen erstrecken, als Grundlage für Entscheidungen dienen. Das Ziel ist dabei die langfristige Sicherung und Maximierung der Datenqualität, um innerbetriebliche Prozesse zu optimieren.
Der Datenqualitätsprozess kann anhand eines Zyklus‘ veranschaulicht werden:
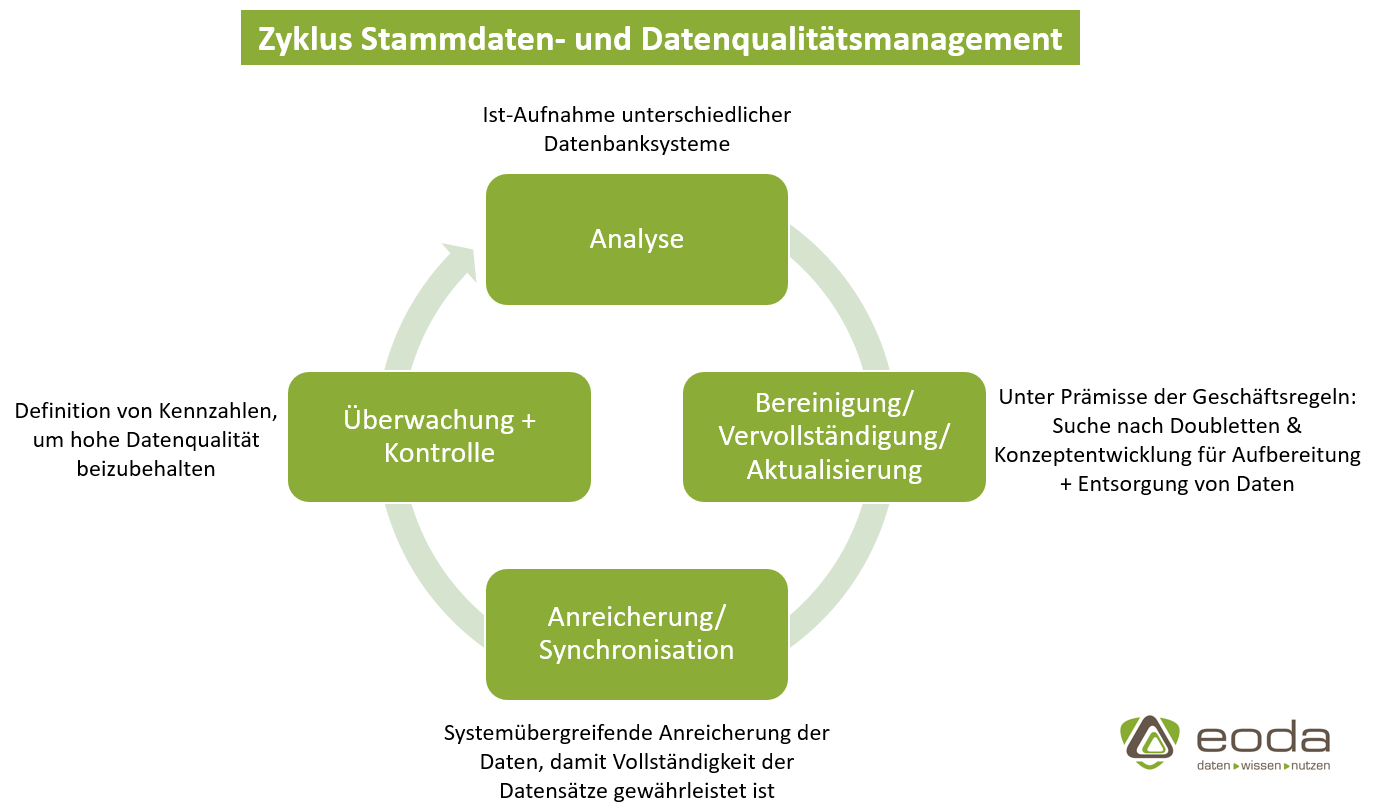
Wie wird Datenqualität beurteilt?
Die Datenqualität steht für die Eignung von Daten für einen bestimmten Zweck – zum Beispiel für weiterführende Analysen. Generell ist der Qualitätsanspruch, dass Daten für den Gebrauch verwendbar und geeignet sind, um unternehmensbezogene Ziele erfolgreich erreichen zu können. Gute Datenqualität bedeutet, dass diese einheitlich, konsistent, vollständig, fehlerfrei, aktuell und vor allem redundanzfrei sind.
Die Datenqualität kann in
- intrinsische Datenqualität
- kontextbezogene Datenqualität
- Darstellungs- und Verfügbarkeitsqualität
unterteilt werden.
Die intrinsische Datenqualität bezieht sich vor allem auf die Aktualität und die Korrektheit der Daten. Die kontextbezogene Datenqualität umfasst, dass die Daten die Anforderungen einer spezifischen Situation erfüllen können. Bei der Darstellungs- und Verfügbarkeitsqualität geht es um die verständliche und widerspruchsfreie Darstellung von Daten, sowie deren schnelle Verfügbarkeit. Werden neue Daten eingegeben, ist es sehr wichtig, dass diese den Qualitätsansprüchen entsprechen. Dies kann unter anderem durch Pflichtfelder bei der Eingabe in die Datenbank geschehen. Es ist folglich von Bedeutung, dass Qualitätssicherungen und vor allem Qualitätskontrollen zyklisch stattfinden.
Wird die Datenqualität im Unternehmen erstmals überprüft und verbessert, findet zunächst eine Analyse des Ist-Zustands statt, um unvollständige Datensätze und sich wiederholende Stammdaten zu ermitteln bzw. zu enthüllen. Dies kann anhand einer Software oder auch von Data Scientists durchgeführt werden.
Warum Sie Wert auf Stammdaten- und Datenqualitätsmanagement legen sollten
Die Einführung einer Software oder einem Datenintegrationsprojekt zur Datenqualitätssicherung erscheint häufig als sehr aufwendig und unkalkulierbar, dennoch gehört es vor allem bei Data-Science-Projekten zur Notwendigkeit, um diese erfolgreich durchführen zu können. Hieraus kann sich ein enormes Potenzial ergeben, welches sich aus den Daten generieren lässt und somit zu wesentlichen Vorteilen für ein Unternehmen führen kann.
Sind Stammdaten gepflegt, können diese einfacher und schneller für Entscheidungen herangezogen werden. Dies kann wiederum zu Wettbewerbsvorteilen gegenüber Unternehmen führen, dessen Stammdaten in irgendeiner Form inkorrekt sind. Zusätzlich können durch effizientere Prozesse Kosten eingespart werden. Außerdem kann dadurch beispielsweise Zeit und Geld bei Projekten für das Datenmanagement eingespart werden.
Ein umfassendes Datenmanagement stellt außerdem die Grundlage für die Datenanalyse dar und gilt als Voraussetzung für erfolgreiche KI-Anwendungen. Um richtige Prognosen zu erhalten, müssen die Daten korrekt und vollständig sein, damit diese für das Lernverfahren der KI verwendet werden können. Beispielsweise lassen sich Lagerbestände nur mäßig verbessern, wenn ca. 30% der Stammdaten fehlerhaft, unvollständig oder doppelt vorliegen. Schlechte Datenqualität kann schlussendlich dazu führen, dass falsche Prognosen entstehen. Das bedeutet, dass aufgrund der Korrektheit der Daten Fehlentscheidungen und falsche Marktaufstellungen durch korrekte Prognosen vermieden werden können.

Es zeigt sich also, dass Stammdaten und deren Qualität das A und O in Ihrem Unternehmen sind. Sind diese vereinheitlicht und gepflegt, haben Sie den Grundstein für nachhaltige Unternehmensprozesse gesetzt.
Sehen Sie Optimierungsbedarf bei der Qualität Ihrer (Stamm-)Daten? In unserem Daten Assessment erhalten Sie eine professionelle Analyse Ihres Datenbestands und konkrete Handlungsempfehlungen für die Steigerung der Datenqualität. Darüber hinaus zeigen Ihnen unsere erfahrenen Datenexperten erfolgsversprechende KI-Anwendungsfälle, die Sie mit Ihren Daten realisieren können.
Starten Sie jetzt durch – wir begleiten Sie dabei!