Text Mining: Unstrukturierte Daten analysieren
Das Bewusstsein für die Bedeutung von Daten und die damit verbundenen Werte ist in den letzten Jahren stetig gestiegen. In nahezu allen Bereichen finden Methoden der Datenanalyse ihre Anwendung, um die so zahlreich anfallenden Daten und die darin enthaltenen Informationen strategisch nutzen zu können. Im Fokus dabei steht aber überwiegend die Analyse gut strukturierter und standardisierter Daten wie sie in Datenbanken oder Dateien vorkommen, da diese Daten leicht nutzbar sind. Doch auch die Analyse vermeintlich unstrukturierter Daten bietet große Chancen, Nutzen aus der steigenden Datenmenge zu generieren. In vielen Bereichen sind konkrete Anwendungen wie Inhaltsanalysen oder Sentiment Detection immer öfter im Gespräch. Natürlich sind der sogenannten qualitativen Datenanalyse auch Grenzen gesetzt. Bei der automatischen Erkennung von Stimmungen oder Einstellungen zeigt sich noch die ein oder andere Hürde, beispielsweise bei mehrdeutigen Aussagen wie „die Reifen sind echt abgefahren“. Doch die, spätestens mit der Verbreitung des Internets entstandene, nahezu unbegrenzte Verfügbarkeit von digitalen Texten und Dokumenten macht die Analyse von unstrukturierten Daten notwendig.
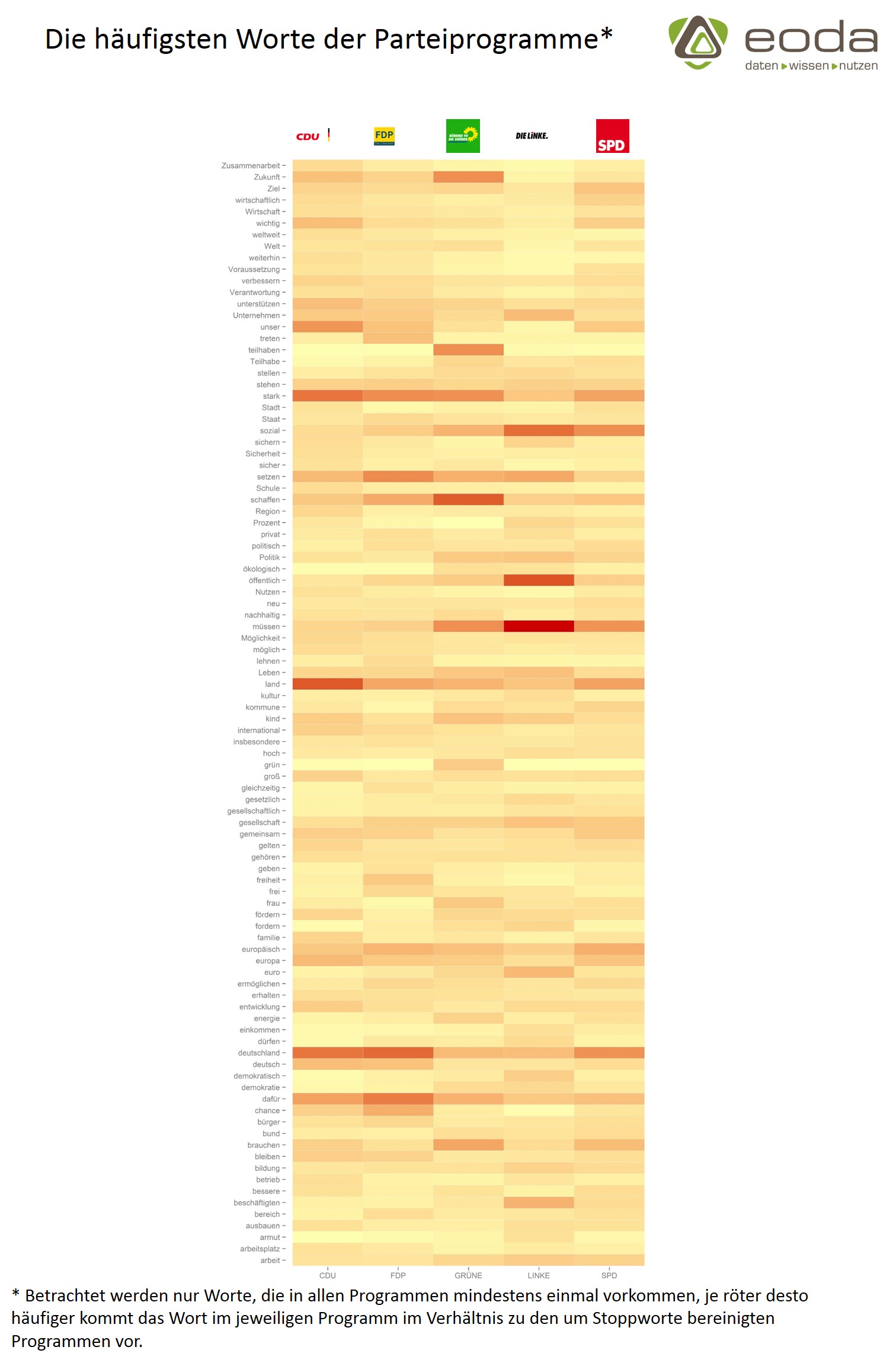
Die häufigsten Worte der Wahlprogramme zur Bundestagswahl 2013:





Die Vielfältigkeit unstrukturierter Daten
Die beschriebene Notwendigkeit begründet sich vor allem in der Vielfältigkeit in der unstrukturierte Daten vorliegen. Diese reicht von E-Mail –Verläufen bis hin zu wissenschaftlichen Artikeln, oder auch Wahlprogrammen. Besonders interessant ist die Betrachtung der sozialen Kommunikationsmedien, die zahlreiche essentielle Informationen bereitstellen. Diese Bandbreite an unterschiedlichen Datenquellen schafft auch ein breites und interdisziplinäres Spektrum an Interessenten, die von der Informationsgewinnung aus unstrukturierten Daten partizipieren möchten. Sowohl Unternehmen, als auch die Wissenschaft zeigen großes Interesse an der Nutzung der beschriebenen Daten. Selbst in der Kriminalitätsaufklärung wird auf die Informationen gesetzt, die aus unstrukturierten Daten gewonnen werden können. Ein Anwendungsfall ist die systematische Untersuchung hunderttausender E-Mails, die vom Management des Pleite gegangenen amerikanischen Energiekonzerns Enron verschickt wurden. Mittels Methoden zur Textanalyse wurde nach besonderen Merkmalen in den Mailverläufen gesucht um die Hauptverursacher der Unternehmenspleite und rechtswidrige Handlungen ans Licht zu bringen – mit Erfolg.
Case-Study: Text Mining zur Prognose der Strompreisentwicklung
Erfahren Sie, wie wir für unseren Kunden eine belastbare Entscheidungsgrundlage für den effizienten Stromhandel realisiert haben.

Text Mining als Methodenlösung
Die Methoden zur Analyse liefert das Text Mining als spezielles Gebiet der qualitativen Datenanalyse. Auf der Basis Algorithmus-basierter Analyseverfahren werden Bedeutungsstrukturen aus schlecht- oder unstrukturierten Textdaten ermittelt. Diese Strukturen versetzen die Anwender in die Lage Kerninformationen der verarbeiteten Texte schneller zu erkennen oder sogar Informationen zu erschließen, die sie zuvor gar nicht in den Dokumenten vermutet haben. Anders als bei reinen Suchmaschinen geht es beim Text Mining nicht nur um das Auffinden von Dokumenten, sondern vielmehr darum automatisiert neues Wissen zu generieren.
Vorteile in vielen Anwendungsbereichen
Dieses Wissen kann echte Wettbewerbsvorteile erbringen. Für Unternehmen ist ein stetiger Überblick über den Markt ein essentielles Anliegen. Durch eine gezielte Analyse von Webseiten, Texten oder Social Media Plattformen können Unternehmen neue Trends, Bedürfnisse der Kunden und potentielle Konkurrenten ermitteln. Dadurch entsteht ein Wissensvorsprung, der die Unternehmensausrichtung positiv beeinflussen kann. Im Kontext empirischer Forschungen können beispielsweise aufkommende gesellschaftliche Probleme oder aktuell besonders präsente Thematiken ermittelt werden, sodass eine frühzeitige Reaktion auf sich anbahnende Entwicklungen möglich ist. So lässt sich moderne Kommunikation analysieren und Zusammenhänge zwischen Themen herstellen. Die Anatomie eines „Twitter-Gesprächs“ offenbart dadurch häufig ungeahnte Inhalte und Verläuf
Die Statistiksprache R bietet umfangreiche Lösungen
Die umfangreichen Datenmengen, die vielfältigen Formate und die unterschiedlichen Aufgabenstellungen machen die Analyse nicht standardisierter Texte äußerst komplex. In diesem Umfeld ist die freie statistische Programmiersprache R eine der führenden Lösungen. R bietet ein unbegrenztes Angebot an Methoden für nahezu jede statistische Problemstellung. Unter anderem erweitert das Erweiterungspaket tm R zu einer performanten und flexiblen Text Minining Anwendung. tm bietet Funktionen für die Verwaltung von Textdokumenten und erleichtert die Nutzung von heterogenen Textformaten in R. Das Paket ermöglicht das Einlesen von E-Mails, RSS Feeds und einer Vielzahl weiterer Dateiformate (HTML, CSV text, PDF etc.). Die Datenstrukturen und Algorithmen können den konkreten Anforderungen angepasst werden, da die Entwickler von tm auf einen modularen Ansatz setzen, der eine einfache Integration von neuen Formaten, Transformationen und Filteroperationen unterstützt. Letztere ermöglichen eine konkrete Filterung der Texte nach bestimmten Kriterien. Der Vorteil bei der Verwendung von R ist, dass die erhaltenen Ergebnisse als Grundlage für weitergehende statistische Untersuchungen unter Verwendung der Statistiksprache dienen können.
Auf http://cran.r-project.org/web/views/NaturalLanguageProcessing.html sind verschiedene Pakete zusammengefasst, die R um Funktionen zu „Natural Language Processing“ wie Stemming, Spracherkennung oder semantische Analyse erweitern.
Die Bedeutung von Text Mining nimmt zu
Die steigende Menge an unstrukturierten Daten bedarf automatisierter Verfahren, um möglichst effizient die benötigten Informationen zu erhalten. Daher wird die Bedeutung von Text Mining Verfahren auch in Zukunft weiter steigen.