Wer regelmäßig Code schreibt, stößt schnell auf die Notwendigkeit zur Versionierung. Im Folgenden soll vorgestellt werden, was darunter zu verstehen ist, welche gängigen Technologien es gibt und wie die Versionierung in Data Science Projekten aussehen kann.

Warum eigentlich Versionierung
Versionierung bezeichnet das regelmäßige Zwischenspeichern von Code. Jedoch unterscheidet sich Versionierung zum üblichen Speichern und Überschreiben dadurch, dass es möglich ist auf vergangene Stände wieder zurückzugreifen. Vorbei sind die Zeiten in denen Dokumente mit Bezeichnungen wie document_v1, document_v2, document_finalversion, document_finalversion2 abgespeichert wurden.
Eine griffige Metapher für Versionierungen kommt von RStudio Chief Scientist Hadley Wickham, der das Versionieren unterschiedlicher Codestände mit der Absicherung im Klettern vergleicht: Häufiges absichern nimmt Zeit in Anspruch, aber verhindert auch ein zu weites zurückfallen bei Fehlern. Je größer die Abstände zwischen Sicherungen desto gravierender die Konsequenzen, wenn mal etwas schief läuft.
Das Abspeichern von unterschiedlichen Codezuständen wird als Commit bezeichnet. Dadurch das Commits kommentiert werden können und ein Vergleich zwischen unterschiedlichen Ständen möglich ist, entsteht eine Dokumentation der Änderungen. Zusätzlich ermöglichen Versionierungssysteme auch das parallele Arbeiten mehrerer Personen an den gleichen Dokumenten.
Versionierungstechnologien
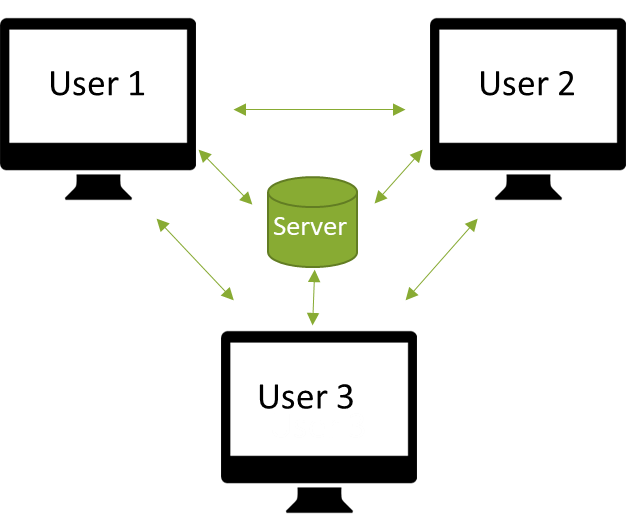
Gängige Technologien zur Versionierung sind git und svn. Wir werden uns im Folgenden mit git beschäftigen. git ist eine freie Software zur Versionsverwaltung von Dateien. Ursprünglich wurde sie zur Versionierung von Quellcode bei der Kernel-Entwicklung von Linux verwendet. git ist dabei ein dezentrales System. Das bedeutet, dass einzelne Personen Kopien des Archivs auf ihrem System haben und ein zentraler Server als Schnittstelle zwischen den einzelnen Usern dient. Für die Verwaltung von git-Verzeichnissen auf Servern stehen verschiedene Cloud Lösungen zur Verfügung, die bekanntesten sind github und gitlab.
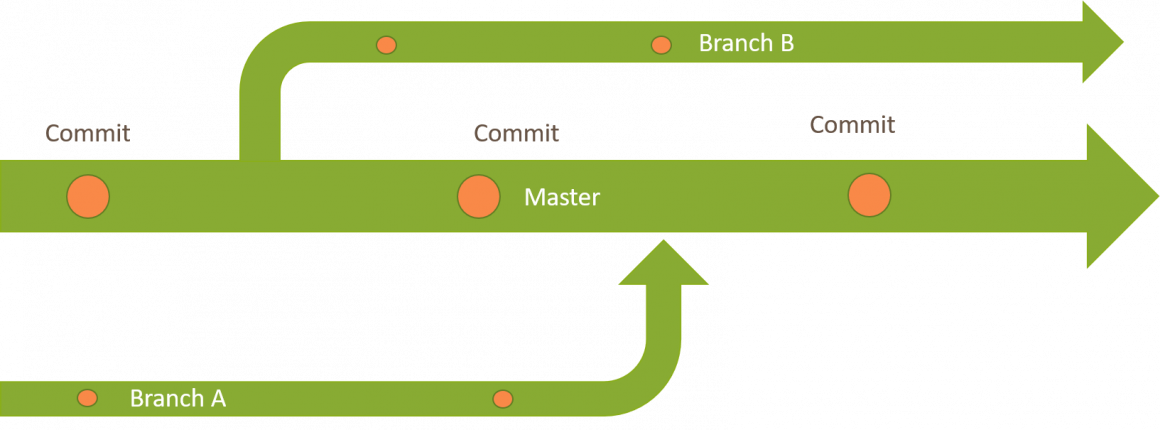
Sollen größere Änderungen an dem bestehenden Code vorgenommen werden, ist es möglich neue Abzweigungen des Codes zu definieren und diese zu einem späteren Zeitpunkt wieder zusammenzuführen. Die einzelnen Abzweigungen werden als Branches bezeichnet, der Standard Branch als master.
Versionierung in Data-Science-Projekten
Es gibt viele Best-Practice-Vorschläge in denen beschrieben wird, wie ein Versionierungs-Workflow aussehen könnte. Auf der Suche nach dem passenden Vorgehen ist zu beachten, dass sich die Entwicklung von Code in Data-Science-Projekten von der Entwicklung von Code in Softwareprojekten unterscheidet. Während in der Softwareentwicklung in Teilen schon recht konkrete Vorstellungen herrschen, wo die Reise einmal hingehen soll, sind Data-Science-Projekte von einer höheren Unsicherheit geprägt. Erstmal geht es um das Testen von Hypothesen und darum, ob sich bestimmte Fragen mit Hilfe der vorliegenden Daten beantworten lassen. So ist eine typische Anforderung an den master Branch in Softwareprojekten, dass dieser immer lauffähig ist. Aber was ist unter lauffähigem Code in Data-Science-Projekten zu verstehen? Hier werden in den ersten Phasen eines Projektes Branches oftmals verwendet um unterschiedliche Analysestrategien zu testen und es kann durchaus vorkommen das manche Branches zu keinen Ergebnissen führen und nicht weiterverfolgt werden. Hat das Projekt den Explorationsstatus verlassen, kann zu gängigen Workflows aus der Softwareentwicklung wie zum Beispiel gitflow übergegangen werden.
Die Verwendung von git erfolgt nativ durch Konsolenbefehle. Es gibt aber für viele Entwicklungsumgebungen entsprechende Point and Click Plugins.
Während Data-Science-Projekten ist es in der Regel nicht nötig den vollen, sehr umfangreichen Funktionsumfang von git zu nutzen, sondern man kommt mit wenigen Funktionen schon sehr weit.
Im Folgenden eine Auflistung der wichtigsten Funktionen:
- pull: Alle Änderungen von einem Remote in das lokale Repository laden und zusammenfügen (Aktualisierung auf lokaler Ebene)
- stage: Definition von Änderungen, die im nächsten commit berücksichtigt werden sollen
- commit: Änderung am Dateisystem in das lokale Repository einpflegen
- push: Das lokale Repository auf einen Remote hochladen
- branch: Erstellen oder löschen von Branches
- merge: Zusammenführen von Branches
Einen guten Einblick über die Nutzung von git in Data Science liefern u.a. Jenny Bryan und Jim Hester unter happygitwithr.com
Erfahren Sie mehr.