Tutorial: Kartenvisualisierung mit R
Inhalt
Die Visualisierung von Regional- und Geodaten ist eines der gefragtesten Themen im Umfeld von R. Das folgende Tutorial gibt einen Einblick in die Kartenvisualisierung mit der freien Programmiersprache.
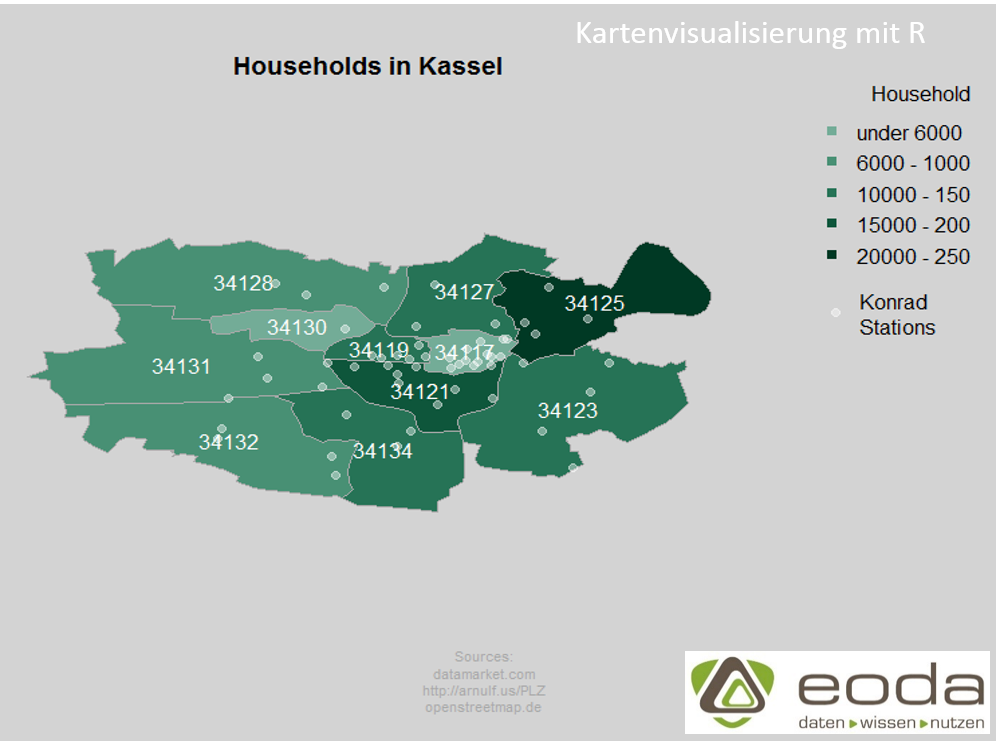
Das Tutorial zeigt die Erstellung einer Karte der Kasseler Stadtbezirke einschließlich der grafischen Darstellung der dort ansässigen Haushalte. Solch ein Kartentyp wird auch als Choropleth Karte bezeichnet. In einem weiteren Schritt werden zusätzlich Stationen des ehemaligen Kasseler Fahrradverleihsystems Konrad eingezeichnet.
Einlesen von Shapefiles
Die Informationen über die Kartenumrisse, sind in einem Shapefile abgelegt. Ein solches Shapefile besteht aus mindestens drei Dateien.
- Eine Datei mit der Endung shp – in ihr werden die geometrischen Informationen zur Darstellung der Karte gespeichert
- Eine Datei mit der Endung dbf – in dieser werden die Attribute der geometrischen Figuren gespeichert. In unserem Fall der Postleitzahlengebiete befinden sich in dieser Datei die Postleitzahlen und die zugehörigen Städtenamen.
- Eine Index-Datei mit der Endung shx – diese ermöglicht das Filtern von den Geometriedaten nach den entsprechenden Attributen. In unserem Beispiel haben wir Postleitzahlen Gebiete für gesamt Deutschland und wollen nur einen Ausschnitt mit den Kasseler Postleitzahlen.
In R lässt sich ein shapefile unter anderem mit dem Befehl readShapeSpatial aus dem maptools Paket einlesen. Wir bekommen ein S4 Objekt der Klasse Large SpatialPolygonsDataFrame. S4 Klassen stellen eine formellere Objektstruktur im Vergleich zu Listen zur Verfügung und ermöglichen ein Objekt orientierteres Arbeiten. Das Objekt lässt sich wie ein Dataframe indizieren.
#subsetting only Kassel shapes
ks_shapes <- shapes[shapes$PLZORT99 == „Kassel“,]
Mit plot(ks_shapes) werden die Umrisse in R dargestellt:
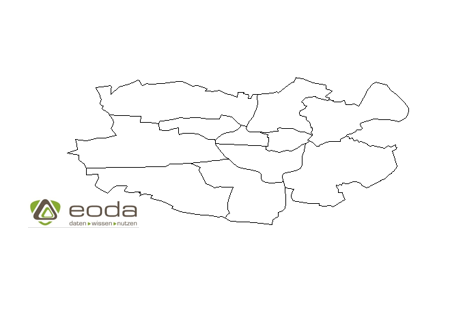
Diese Karte reichern wir mit weiteren Informationen an.
Datenmanagement
Die entsprechenden Daten stammen von der Seite datamarket.com und wurden von der Fachstelle für Statistik Kassel zur Verfügung gestellt. Die genannten Daten sind auf Stadtteilebene angegeben, die Karte jedoch basiert auf den Postleitzahlen. Daher ist noch ein weiterer Datensatz nötig, der die Stadtteile den entsprechenden Postleitzahlgebieten zuordnet. Eine solche Zuordnung kann man z.B. bei Wikipedia finden.
In R mit read.csv2 eingelesen sehen die Daten wie folgt aus:
stringsAsFactors = FALSE)
districts_ks
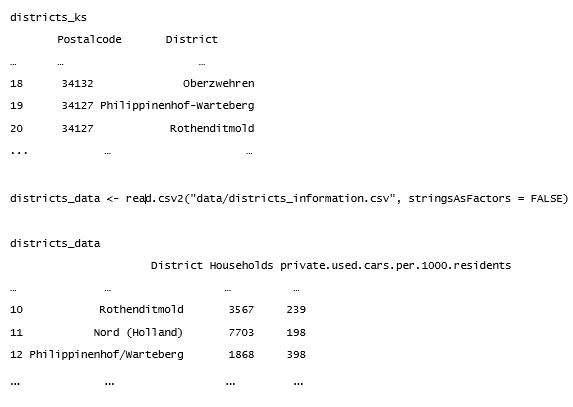
districts_data <- read.csv2(„data/districts_information.csv“, stringsAsFactors = FALSE)
districts_data
District Households private.used.cars.per.1000.residents

District Households private.used.cars.per.1000.residentsUm die beiden unterschiedlichen Datensätze miteinander zu verbinden, ist es nötig die District Variablen in eine einheitliche Struktur zu bringen. Beispielsweise haben wir in einem Datensatz die Bezeichnung „Philippinenhof-Warteberg“, in dem anderen die Bezeichnung „Philippinenhof/Warteberg“. In diesen kleinen Datensätzen ändern wir die Bezeichnungen einfach durch Indizierung und Zuweisung. (Für größere Datensätzen sollte vorher eine systematische Datenbereinigung durchgeführt werden. Helfen könnten hierbei z.B. Regular Expressions, mit denen sich Texte anhand von Mustern durchsuchen lassen.)
districts_data$District[districts_data$District == „Nord (Holland)“] <- „Nord-Holland“
districts_data$District[districts_data$District == „Philippinenhof/Warteberg“] <- „Philippinenhof-Warteberg“
districts_data$District[districts_data$District == „Süsterfeld/Helleböhn“] <- „Süsterfeld“
districts_data$District[districts_data$District == „Wolfsanger/Hasenhecke“] <- „Wolfsanger-Hasenhecke“
Die beiden Datensätze werden anschließend mit merge zusammengeführt.
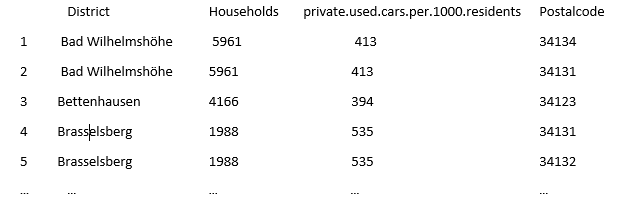
Es entstehen doppelte Einträge für District und Postalcode. Als nächsten Schritt werden wir die Daten so zusammenfassen, dass wir eindeutige Einträge für die Variable Postalcode erhalten. Dabei summieren wir die jeweiligen Werte von Households, und schreiben die zugehörigen Districts in einen String. Zur Aggregation greifen wir auf das Datenmanagement Paket dplyr
zurück, welches eine eigene Grammatik des Datenmanagements mit sich bringt. Ein wichtiger Bestandteil ist der Pipe Operator %>%. Ursprünglich aus dem magrittr-Paket, lassen sich mit %>% Funktionsaufrufe aneinander Ketten ohne dass jedes Mal der Datensatz manuell aufgerufen werden muss.
data.agg %group_by(Postalcode)%>%summarise(District = paste(unique(District),collapse = “ & „) , Households = sum(Households),cars = sum(private.used.cars.per.1000.residents))
Der resultierende Datensatz sieht dann wie folgt aus:

Eine Ungenauigkeit die durch diese Methode entsteht, ist, dass wir nicht genau wissen wie sich die Einwohner Verteilung der Bezirke über die Postleitzahlengebiete verteilt. Beispielsweise wie viele der 5040 Haushalte des Stadtteils Mitte entfallen für das Postleitzahlengebiet 34121 und wie viele auf 34117?
Damit die Daten schließlich auf der Karte visualisiert werden können müssen sie noch in Klassen unterteilt werden.
Mit der Funktion cut erstellen wir einen Faktor, der die entsprechenden Klassen enthält. Im nächsten Befehlsaufruf weisen wir diesen Klassen Bezeichnungen zu.
levels(classes) <- c(„under 6000“, „6000 – 10000“, „10000 – 15000“, „15000 – 20000″,“20000 – 25000“)
Wir erstellen des Weiteren noch einen Farbvektor, der fünf unterschiedliche Grüntöne enthält.
Grafik erstellen
Zur Darstellung der Karte benutzen wir die Grafik Funktionen aus Base R. Als erstes setzen wir globale Parameter der Grafik.
bg = „lightgrey“,xpd = TRUE)
Mit mar = c(0,0,1,9) definieren wir die inneren Ränder der Grafik. Wir wollen unten und links keinen inneren Rand, oben einen inneren von einer Zeile und auf die rechte Seite soll unsere Legende, für die wir mit neun Zeilen einen etwas breiteren Rand definieren. Mit oma = c(3,0,2,1) definieren wir die Größe der äußeren Ränder. bg = „lightgrey“ legt fest, dass unsere Grafik einen hellgrauen Hintergrund bekommt. Durch Setzen des Arguments xpd = TRUE stellen wir sicher, dass die Legende auch innerhalb des inneren Rahmens dargestellt wird.
Mit plot zeichnen wir schließlich unsere Karte, wir umranden die Postleitzahlgebiete dunkelgrau und übergeben als Farben unseren colours Vektor, sortiert nach classes (Anzahl der Haushalte in Klassen)
Die Funktion text(coordinates(ks_shapes), labels =ks_shapes$PLZ99_N, col = „white“) fügt den Bereichen noch Label in Form der Postleitzahlen hinzu.
Eine Legende kann durch den Funktionsaufruf legend() hinzugefügt werden.
xjust = -3.4, yjust = -1.8)
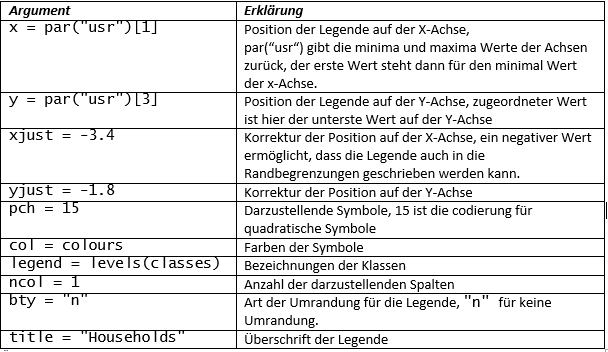
Mit title(„Households in Kassel“) fügen wir der Grafik schließlich noch eine Überschrift hinzu.
Integration von Informationen von openstreetmap.de
Die Informationen über die Koordinaten der Stationen des ehemaligen Fahrradverleihsystems Konrad stammen aus einer osm Datei die sich über das Stadtgebiet Kassel erstreckt. Unter diesem Link kann man sich solch eine Datei herunterladen. Die Datei selbst ist in einer xml Struktur aufgebaut.
Um die Konrad Koordinaten aus dieser Datei zu ziehen gibt es zwei unterschiedliche Möglichkeiten:
osm parsen mit osmar Paket
Die erste Variante greift auf das Paket osmar zurück, was sich speziell dem Umgang mit openstreetmap Daten widmet. Mit den Befehlen osmsource_file und get_osm wird die Datei eingelesen und die hinterlegten Informationen werden in einem osmar Objekt abgelegt.
Hierbei ist zu beachten das dies für sämtliche Informationen, die für das Stadtgebiet Kassel hinterlegt sind gemacht wird und nicht nur für die gewünschten Konradstationen. Dementsprechend benötigt der Prozess auch recht viel Rechenleistung und das resultierende Objekt ist fast 40MB groß.
Möchte man schließlich an die entsprechenden Nodes der Konradstationen gelangen, sucht man sich zuerst mit find(OBJ, node(tags(v %agrep% „Konrad“))), die passenden IDs der Konrad Knoten heraus und bildet mit subset(OBJ, node_ids = konrad_id), ein entsprechendes Subset des osmar Objekts, dass nur die Konradknoten beinhaltet.
Osm parsen mit xpath
Eine effizientere Methode für unseren Anwendungsfall ist eine gezielte xpath Abfrage. Xpath ist eine Abfrage Sprache mit dem Ziel Informationen aus einem xml Objekt zu erhalten. Das Paket xml bietet dazu eine Funktionsumgebung in R.
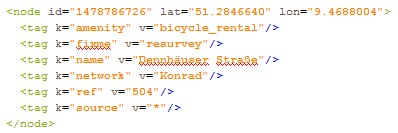
Mit xmlParse(„Kassel.osm“) wird das Dokument in R eingelesen, im nächsten Schritt senden wir jeweils eine Abfrage für die Breitengrade und eine Abfrage für die Längengrade und schreiben das Ergebnis direkt in einen data.frame.
lon = xpathSApply(osm, path = „//node[tag[@v = ‚Konrad‘]]/@lon“),
stringsAsFactors = FALSE)
Als Argument von path übergeben wir einen xpath Befehl der uns heraussucht in welchen Knoten es einen tag Knoten gibt mit einem Attribut v dessen Wert Konrad ist und von diesem Knoten lassen wir uns den Wert des Attributs lat ausgeben.
<
Mit points(stations$lon, stations$lat, col = adjustcolor(„white“,0.4),pch = 19)tragen wir in die schon bestehende Grafik die Konradstationen als weiße Punkte ab, mit adjustcolor(„white“,0.4) machen wir die weiße Farbe etwas transparenter. Wir fügen noch ein weiteres Legenden Element hinzu.
xjust = -5.1, yjust = -4)
Und als Abschluss fügen wir noch eine Quellenangabe ein.
Die Funktion mtext steht für margin text und erlaubt es Texte in die Ränder einer Grafik zu schreiben, side = 1
steht für Text im unteren Rand, line = 1 für Text in der zweiten Zeile (die Funktion fängt an bei 0 zu zählen), outer = TRUE steht dafür das der Text in den äußeren Rand geschrieben werden soll, cex und col stehen schließlich für Schriftgröße und Schriftfarbe.
Die Visualisierung von Analyse-Ergebnissen sowie die Erstellung hochwertiger auch interaktiver Grafiken mit R ist eines der Themen in den eoda Data Science Trainings.
Weiterführende Themen

Data-Science-Software:
YUNA – Data Science Projektplattform
Zentrale Plattform für Modelloptimierung, Ausführung und Verwaltung verschiedener Modelle und Skripte.
Erstellen und Verwalten Sie schnell KI-gestützte Services!

Whitepaper:
Shiny Development Guide
Sie sind bereits mit RStats vertraut, kennen die am häufigsten verwendeten Pakete und haben bereits Shiny Apps entwickelt? Laden Sie sich unseren kostenlosen Shiny Development Guide herunter und profitieren Sie von diesem Best Practice Ansatz, um den Entwicklungsprozess von Shiny Apps zu steuern.
Lösungen:
Full-Service R-Studio Partner
Wir sind der führende deutsche RStudio-Partner für Beratung, Beschaffung, Integration und Training:
Erfahren Sie mehr zu unserem Angebot rund um die professionellen RStudio Produkte und Shiny-Apps.

Überblick:
Data Science Software
Mit bewährten Software-Lösungen, die sich nahtlos in Ihre Infrastruktur integriert lassen wir Ihre Projekte Realität werden. Wir sind Ihr Ansprechpartner für Ihre unternehmensweite Analytikplattform, smarte Business-Lösungen, RStudio-Produkte sowie Anaconda Vertriebspartner!