Setup – Architektur, Load-Testing-Tools & Testanwendung
Im Zentrum stehen dabei zwei RStudio-Connect Server und ein Load-Balancer, welcher gleichzeitig ein geteiltes Dateisystem und eine Postgres-Datenbank für die Connect-Server zur Verfügung stellt.


Als Load-Testing-Tools verwenden wir das von RStudio zur Verfügung gestellte R-Paket shinyloadtest und die zugehörige Java-Applikation shinycannon.
Die Funktionsweise der Tools lässt sich anhand des obigen Bildes erklären:
Das Paket shinyloadtest bietet die Möglichkeit, eine Shiny-Applikation zu öffnen und eine beliebig lange Nutzer-Session aufzuzeichnen. Die aufgezeichnete Session kann dann unter Angabe eines Links zur Applikation von shinycannon zum Load-Testing verwendet werden. Dabei wird eine feste Anzahl von Nutzern (sog. „Workern“) angegeben, welche in einem gewählten Zeitraum so oft wie möglich versuchen die aufgezeichnete Session auf dem Server auszuführen. Zum Schluss kann aus den gesammelten Daten des Load-Tests ein Report generiert werden, welcher im nächsten Abschnitt genauer betrachtet wird.
Testanwendung
server <- function(input, output) {
output$distPlot <- renderPlot({
x <- rep.int(faithful[, 2], times = 1000)
bins <- seq(min(x), max(x), length.out = input$bins + 1)
hist(x, breaks = bins, col = 'darkgray', border = 'white')
})
}
Unsere Test-Applikation unterscheidet sich im Wesentlichen kaum von der Shiny-Beispielapplikation, bis auf die für das Histogramm verwendete Datenmenge. Dies stellt sicher, dass jede gestartete Session stets ausreichend Belastung generiert.
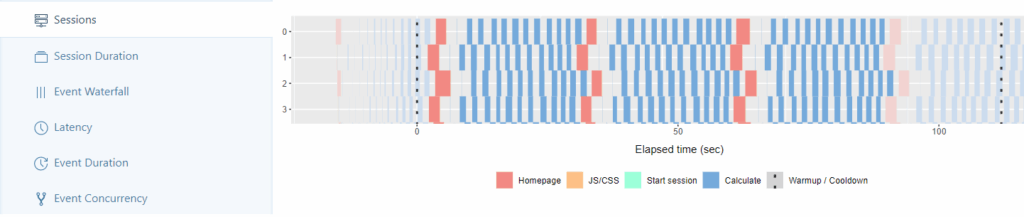
Im Sessions-Tab können die von den Workern gestarteten Sessions analysiert werden. In unserem Beispiel schafft jeder Worker ca. 3-4 Sessions während des von uns gewählten Zeitraums von zwei Minuten. Die Breite der Blöcke spiegelt dabei die benötigte Berechnungszeit wider, die jeder Schritt in der von uns aufgezeichneten Session benötigt.
Erfahrung: Bei einer Anzahl von Workern > 300 fallen zuerst breiter werdende Blöcke auf. Außerdem lassen sich zum ersten Mal signifikant breite türkise und gelbe Blöcke erkennen, welche den Start der Sessions und das Laden der JS/CSS-Files beschreiben.
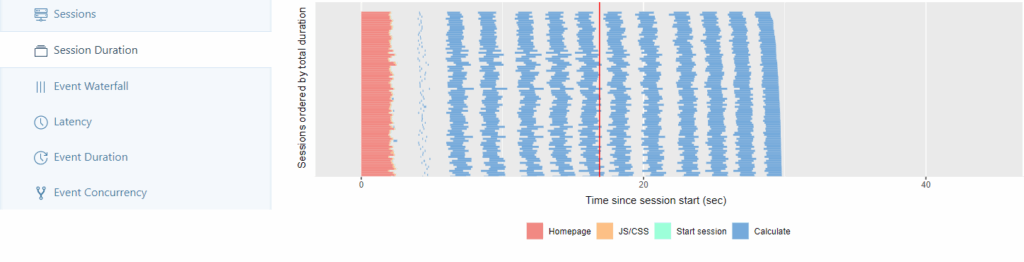
Im Session Duration-Tab findet sich jede gestartete Session von allen Workern der Ausführungszeit nach aufsteigend sortiert.
Erfahrung: Bei einer Anzahl von Workern > 200 zeichnet sich ca. ab dem letzten Drittel der Sessions eine deutliche Steigerung der Ausführungszeit ab.
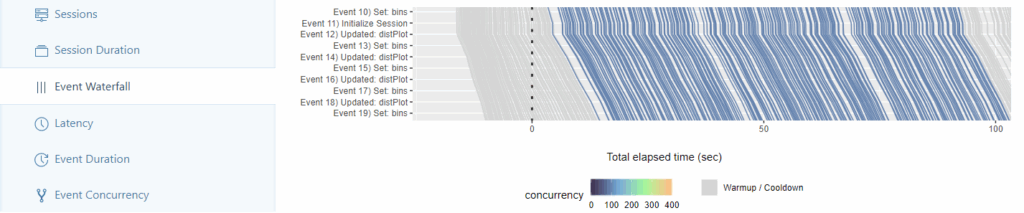
Im Event-Waterfall-Tab wird die aufgezeichnete Session in ihre einzelnen Events unterteilt (bspw. Anpassen des Histogramms – Neuzeichnung des Plots, …). Jede gestartete Session durchläuft als Linie von oben bis unten alle Events und wird anhand der verstrichenen Zeit gezeichnet. Verlaufen die Linien von zwei gestarteten Sessions parallel, benötigen sie dieselbe Zeit, um die aufgezeichnete Session auszuführen.
Erfahrung: Bei einer Anzahl von Workern > 200 beginnen sich Unregelmäßigkeiten in der Parallelität der Linien abzuzeichnen, sodass Sessions ab einem gewissen Zeitraum eine stärkere Tendenz nach rechts aufweisen.
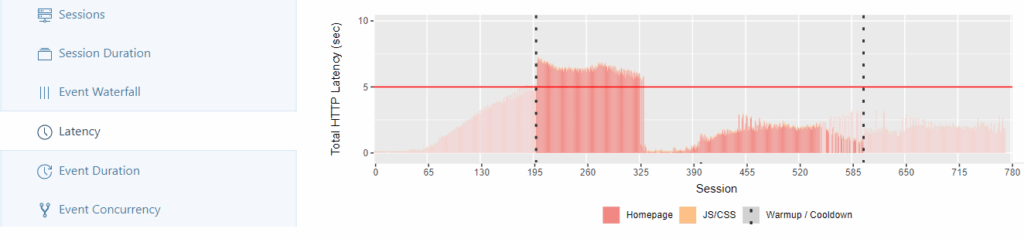
Im Latency-Tab wird für jede Session die Zeit dargestellt, die für HTTP-Anfragen und das Laden der JS/CSS-Dateien benötigt wird. Die rote Linie symbolisiert dabei einen Referenzwert von 5 Sekunden, an dem die Verteilung der Ladezeiten gemessen werden kann (Hier nicht gezeigt ist der zweite Reiter des Tabs, in dem die Reaktionszeit von Shiny für Berechnungen gemessen und äquivalent dargestellt wird).
Erfahrung: Bei einer Anzahl von Workern > 200 überschreiten die ersten Sessions den gesetzten Referenzwert. Bei einer Anzahl von Workern > 400 machen sich zum ersten Mal die Ladezeiten der JS/CSS-Dateien deutlich bemerkbar.
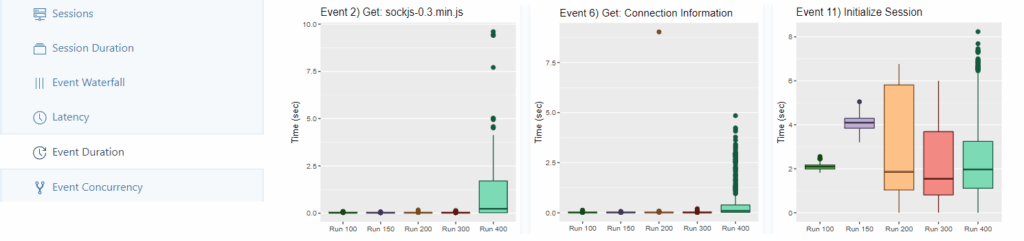
Im Event-Duration-Tab wird für jeden Lauf ein Boxplot für jedes einzelne Event dargestellt, absteigend geordnet nach der längsten gemessenen Zeit.
Erfahrung: Bei einer Anzahl von Workern > 400 enthalten die Boxplots zum ersten Mal über die meisten Events hinweg konsistent Ausreißer. Ferner finden sich erst hier für viele Events signifikante Ladezeiten, welche bei den Läufen mit weniger Workern kaum ins Gewicht fallen.
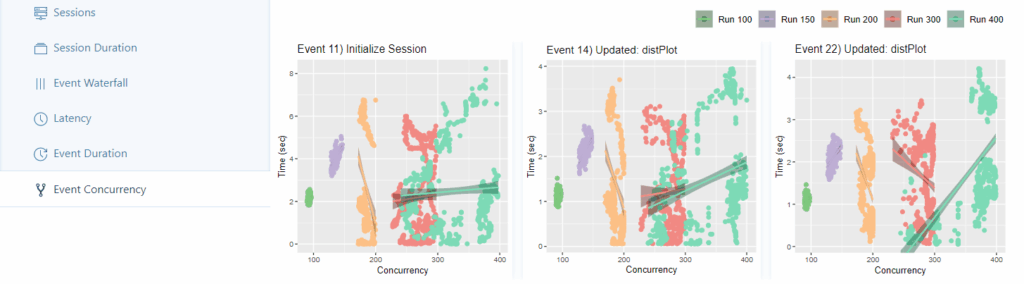
Im Event-Concurrency-Tab wird für jeden Lauf ein Scatterplot für jedes Event dargestellt, basierend auf der Anzahl gleichzeitiger Nutzer. Für jeden Lauf wird eine Regressionsgerade an den Plot angepasst und dann absteigend nach größter gemessener Steigung der Geraden sortiert (In den anderen Reitern wird nach größtem gemessenen Achsenabschnitt/größtem gemessenen Fehler sortiert. Außerdem lassen sich die Ergebnisse der Regressionsmodelle in einer Tabelle abrufen).
Erfahrung: Bei einer Anzahl von Workern > 300 zeichnet sich zum ersten Mal eine breitere Verteilung der Punkte im Scatterplot ab. Die Anzahl der gleichzeitig aktiven Nutzer tendiert aufgrund von höheren Ladezeiten in Richtung 250 – 300. Bei einer Anzahl von Workern > 400 vergrößert sich dieses Intervall wie zu erwarten auf 250 – 400 gleichzeitig aktive Nutzer.
Fazit & Ausblick
Der Schritt vom Prototyp zur Business-Applikation kann viele Hürden mit sich bringen, die es im Laufe des Skalierungsprozesses zu bewältigen gilt. In vielen Fällen werden nicht nur die Nutz- und Belastbarkeit der App, sondern auch kleinere Problemstellen zu signifikanten Problemen skaliert. Diese können ebenfalls eine instabile oder fehlerhafte Applikation zur Folge haben. Ein detailliertes Load-Testing kann dabei eine essenzielle Hilfestellung leisten, potenzielle Schwachstellen früh genug zu erkennen und zu beseitigen, bevor die Applikation in den Produktivbetrieb geht. Wie genau diese Problembehandlung aussehen kann, werden wir in Teil 3 und Teil 4 unserer Blogserie unter die Lupe nehmen, in denen wir uns mit der In-App-Optimierung von Shiny-Applikationen beschäftigen. Unser theoretischer Artikel legt Ihnen den Grundstein für das selbstständige Testen der App.
Beratung, Entwicklung, Infrastruktur und Betrieb: Seit über 15 Jahren sind wir der führende Ansprechpartner rund um die Programmiersprache R - auch im Bereich Wissenstransfer.
![]()
Veröffentlicht: 30. Januar 2020
AutorIn
Starten Sie jetzt durch:
Wir freuen uns auf den Austausch mit Ihnen.