Plan/Apply/Destroy: Cloud-Infrastrukturen mit Terraform
AWS, Azure, Google Cloud, … – Cloud-Provider sind aus der modernen Analyse-Infrastruktur kaum noch wegzudenken. Mit steigendem Datenaufkommen und stetig wachsenden Anforderungen an die Infrastruktur geht der Weg immer häufiger in die Cloud, sei es durch die Portierung bestehender On Premises Architekturen oder dem direkten Aufbau innerhalb der Online-Plattformen. Die Cloud stellt Services und Rechenleistungen in einem Umfang bereit, in dem diese gerade benötigt werden. So werden Prozesse am Laufen gehalten, Kosten eingespart und komplexe Berechnungen in Data-Science-Projekten können durchgeführt werden. Die Gründe für eine Cloud-Infrastruktur sind vielfältig. So lassen sich viele Anforderungen wie beispielsweise Hochverfügbarkeit und Georedundanz (die Spiegelung der Infrastruktur über mehrere Länder) oft nativ auf den verschiedenen Plattformen abbilden. Weiterhin stellen zahlreiche Dienste wie Mail-/Datenbank-/DNS-Services und komplette Machine-Learning-Frameworks viele Möglichkeiten zur Verfügung, Prozesse zu vereinfachen und Workflows zu optimieren. Dabei bieten sich, wie auch bei On Premises Infrastrukturen, verschiedene Optionen der Implementierung, wie zum Beispiel über die Benutzeroberfläche oder per Command-Line-Interface (CLI).
In diesem Artikel beschäftigen wir uns mit HashiCorps Open-Source IaC-Tool (Infrastructure-as-Code) Terraform. Terraform hilft uns dabei, den Aufbau der Cloud-Infrastrukturen in einem Skript festzuhalten und somit eine einfache Möglichkeit liefert, komplette Infrastrukturen zu starten, stoppen und anzupassen. In diesem Artikel wird die theoretische Grundlage von Terraform erklärt, um im folgenden Teil diese praktisch umsetzen zu können.
Deskriptive Konfigurationssprachen – Das Konzept von Terraform
In einem unserer vorherigen Artikel haben wir das IaC-Tool Ansible vorgestellt, mit dem die Konfigurationen von Servern in Form von Skripten definiert werden, um diese dann einheitlich auf beliebig vielen Maschinen auszurollen – ohne jeden Server händisch konfigurieren zu müssen. Die Definition der benötigten Ressourcen erfolgt in einer Beschreibung der gewünschten IST-Zustände, beispielsweise welche Systemprogramme nach Durchlauf des Skriptes auf dem System vorhanden sein sollen. Die genaue Umsetzung der vom Skriptautor definierten Anforderungen wird dann von der Skriptsprache übernommen.
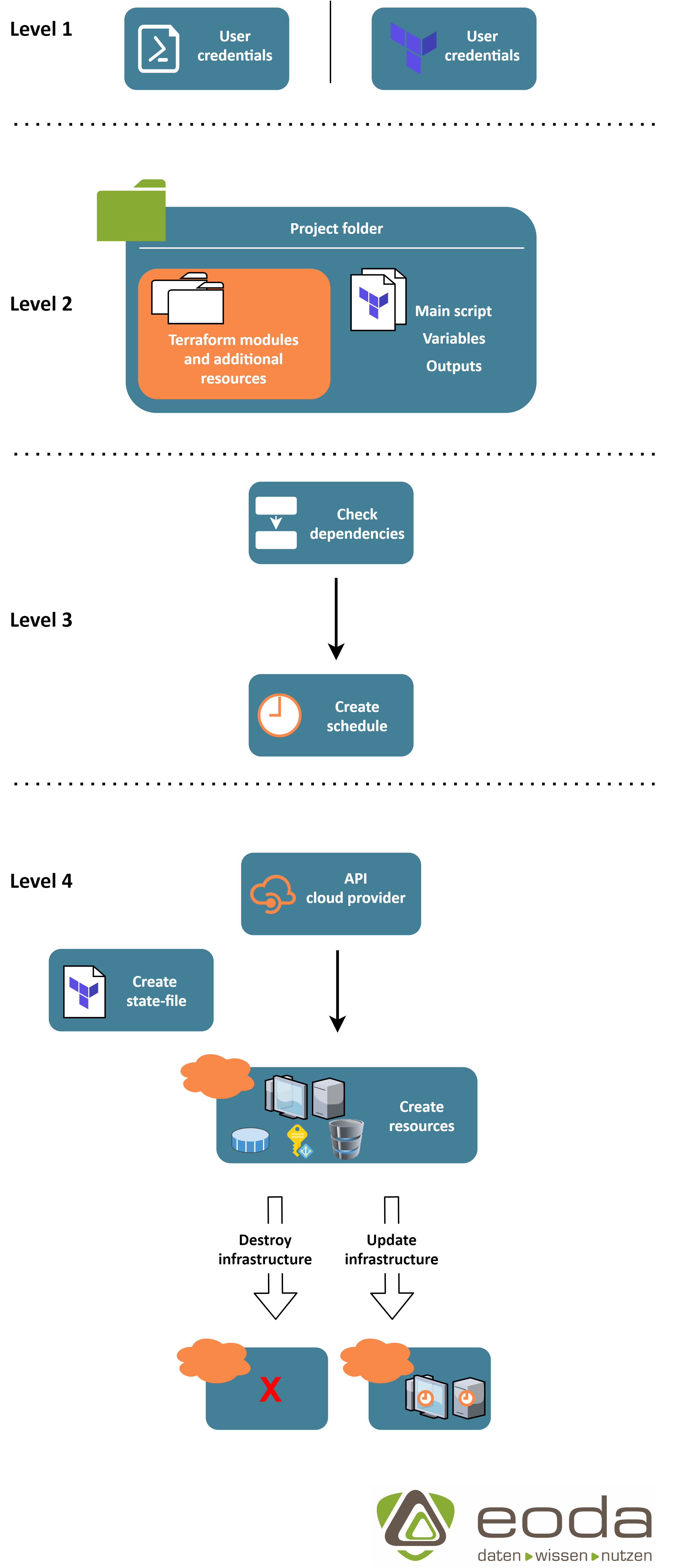
Terraform bedient sich derselben Methodik, nur dass hier die gewünschten Ressourcen beschrieben werden, welche nach Durchlauf des Skriptes in der Cloud-Infrastruktur vorhanden sein sollen. Der Workflow gestaltet sich dabei wie folgt:
Level 1: Um Zugriff auf den Cloud-Anbieter, auf dem die Infrastruktur aufgebaut werden soll, zu erhalten, benötigt Terraform die nötigen Accountinformationen. Diese können beispielsweise über das CLI-Tool des Anbieters vorkonfiguriert oder in Terraform direkt hinterlegt werden.
Level 2: Als nächstes werden die Anforderungen an die Infrastruktur in Form von Terraform-Skripten definiert. Hier werden alle benötigten Ressourcen aufgeführt, Variablen gesetzt und Module implementiert. Wie genau sich der Projektaufbau gestaltet, wird im nächsten Abschnitt behandelt.
Level 3 (optional): In der Planungsphase wird der spätere Aufbau der Ressourcen von Terraform durchgeplant und in Form eines Ablaufplans dargestellt. Da Terraform die nötigen Abhängigkeiten innerhalb der Skripte selbst ermittelt, ist dies eine gute Möglichkeit, sich einen Überblick über den geplanten Aufbau zu verschaffen und ggf. noch zusätzliche, notwendige Abhängigkeiten selbst zu definieren.
Level 4: Beim Deployment verwendet Terraform die vom Anbieter zur Verfügung gestellten APIs, um die Ressourcen auf der Cloud-Plattform hochzufahren. Währenddessen erzeugt Terraform eine sogenanntes state-File, welche den aktuellen Stand der Infrastruktur widerspiegelt. Diese kann später für Update-Prozesse verwendet werden und ist essenziell für einen strukturierten Abbau der Infrastruktur.
Nach erfolgreicher Ausführung des Skriptes kann die Infrastruktur nach Belieben mit Terraform in einen Update-Prozess überführt oder wieder abgebaut werden.
TF- und State-Files – Klassischer Projektaufbau
Wie bei den meisten Programmier-/Skriptsprachen folgt Terraform einem „klassischen“ Konzept zum Projektaufbau, welches sich bei Bedarf individualisieren lässt. Dieses sieht wie folgt aus:
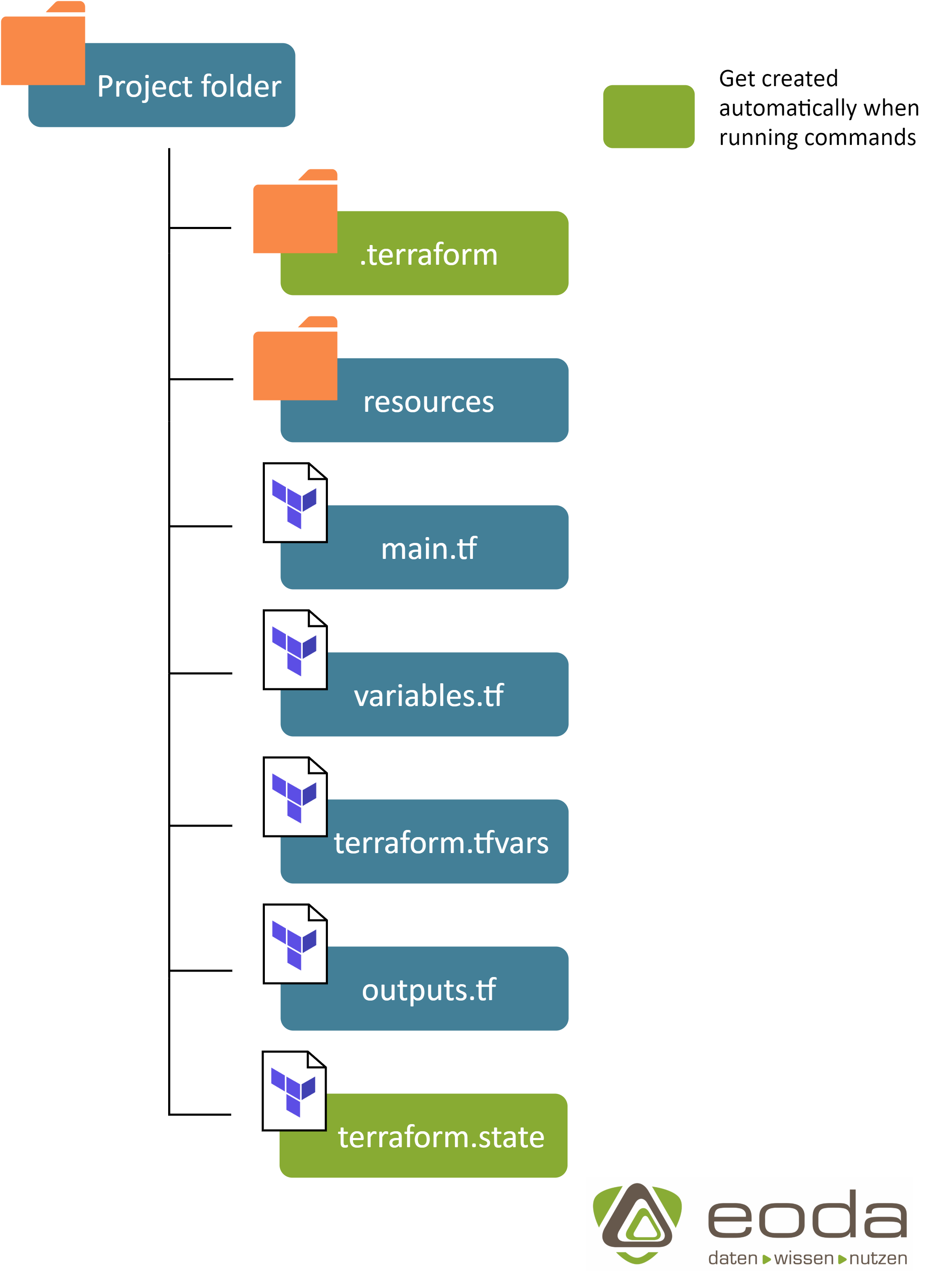
main.tf: Enthält die Definition aller benötigten Ressourcen und Abhängigkeiten.
variables.tf: Enthält die Definition aller Variablen, welche im Main-Skript verwendet werden.
terraform.tfvars: Füllt die Variablen aus dem Variables-Skript mit den gewünschten Werten.
outputs.tf: Definiert alle Informationen, welche nach erfolgreicher Ausführung des Skriptes ausgegeben werden sollen (z.B. IPs von Servern oder API-Endpunkte)
terraform.state: Enthält, wie im vorigen Abschnitt bereits angesprochen, alle Informationen über den aktuellen Stand der Infrastruktur und wird während des Deployments von Terraform erstellt. terraform.state sollte im Fall eines kollaborativen Projektes zentral gespeichert werden, da Informationen über eine Veränderung der Infrastruktur nur lokal verfügbar sind.
resources: Enthält alle zusätzlichen Ressourcen (z.B. vorgefertigte Konfigurationsdateien), welche für die erfolgreiche Provisionierung der Infrastruktur notwendig sind.
.terraform: Wird von Terraform selbst erstellt und enthält alle Module, welche im Main-Skript verwendet werden, um die verschiedenen Ressourcen anzusprechen.
Prozess-Keywords – Die Arbeitsweise von Terraform
Ein Vorteil bei der Arbeit mit Terraform liegt in der einfachen Ansteuerung der einzelnen Prozesse durch bedeutende Keywords. Ein klassischer Prozess in einem Terraform-Projekt gestaltet sich dabei meistens wie folgt:
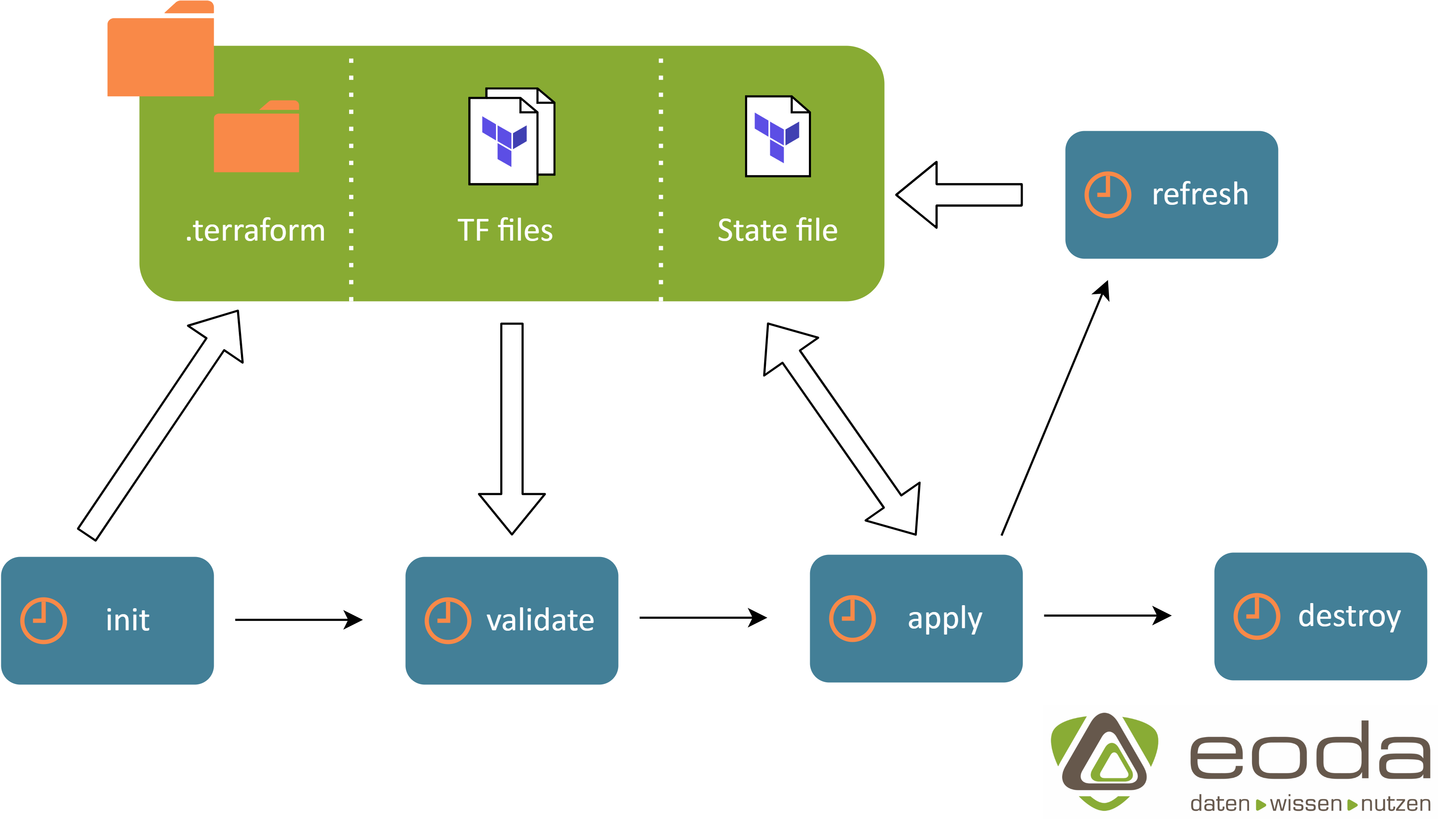
Mit terraform init lassen sich alle von Terraform benötigten Ressourcen automatisiert herunterladen und initialisieren. Mit terraform validate lassen sich die Skripte auf Syntax- und Logikfehler überprüfen.
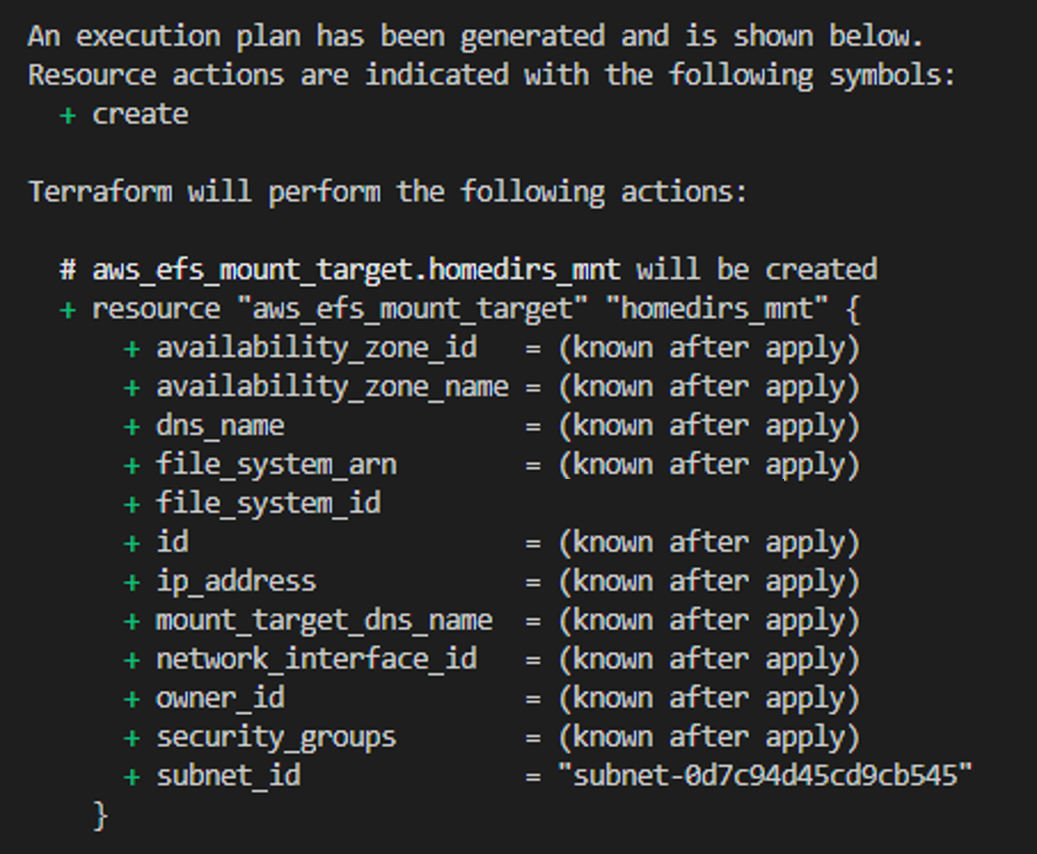
Mit terraform plan lässt dich der bereits angesprochene Ablaufplan erstellen. In diesem lässt sich ablesen, welche Ressourcen erstellt(+)/geändert(~)/zerstört(-) werden. Außerdem führt Terraform hier die Reihenfolge an, in der es die Erstellung der Ressourcen plant. Der Screenshot zeigt einen beispielhaften Ablaufplan zum Aufbau einiger Ressourcen.
Auch wenn dieser Schritt optional ist, ist es in den meisten Fällen sinnvoll, die Abhängigkeiten vorher durchzuplanen und händisch nachzuprüfen.
Mit terraform apply kann die Infrastruktur deployed werden. Dies kann unter Angabe eines Plans ausgeführt werden oder direkt und ohne eine vorherige Planung. Hiermit wird im Falle einer Änderung auch der Update-Prozess gestartet.
Mit terraform refresh kann das aktuelle state-File mit der vorhandenen Infrastruktur synchronisiert werden. Dies ist notwendig, da das state-File die einzige Informationsquelle über die aktuelle Infrastruktur für Terraform ist. Update-/Planungs- und Löschprozesse werden gegen den state angepasst, weswegen dieser bei vorhandener Infrastruktur vor jedem der Prozesse aktualisiert werden sollte.
Mit terraform destroy kann die Infrastruktur schlussendlich wieder abgebaut werden. Auch hier wird ein Abbauplan ausgegeben. Dieser kann verifiziert und muss bestätigt werden.
Fazit
Das Open-Source-Tool von Hashi-Corp ermöglicht es durch seine intuitive Bedienung und flexiblen Anwendungsmöglichkeiten eine Umgebung strukturiert zu planen, aufzubauen, zu verändern und abzubauen. Terraform als IaC-Tool bietet eine nahtlose Integration in neue oder bestehende DevOps-Prozesse und vereinfacht somit zahlreiche Cloud-Infrastruktur-Workflows nachhaltig. Im ersten Teil unseres Terraform-Artikels wurden nun die theoretischen Grundlagen der Arbeits- und Funktionsweise erklärt, um mithilfe des kommenden Beitrags eigenständig ein Terraform-Projekt von der Konzeption bis zum Deployment durchführen zu können.
Sie möchten Cloud-Infrastrukturen in Ihrem Unternehmen aufbauen? Wir entwickeln ihre “enterprise ready” Infrastruktur – Erfahren Sie mehr und sprechen Sie uns an!
Erhalten Sie außerdem einen Einblick in unser letztes Projekt in Zusammenarbeit mit der Universität Amsterdam! Mehr dazu in unserer Case Study zum Aufbau einer Cloud-Infrastruktur mit Terraform & RStudio Server.