
Deep Learning und Autoencoder
Kosten sparen durch schnelle Anomalieerkennung
Schnelles Erkennen von Anomalien spart oft viel Geld, auch kleine Verbesserungen können schon finanzielle Einsparungen bedeuten. Die Herausforderungen in der Anomalieerkennung sind vielfältig. Die Seltenheit des Auftretens, Heterogenität in den Anomalien und wenig Wissen über die Anomalien, bevor sie das erste Mal auftreten, sind in fast jeder Anwendung zur Anomalieerkennung herausfordernd. Zusätzlich gibt es oft Herausforderungen, die abhängig vom Anwendungsbereich sind.

Deep Learning und Autoencoder
Kosten sparen durch schnelle Anomalieerkennung
Schnelles Erkennen von Anomalien spart oft viel Geld, denn auch kleine Verbesserungen können schon finanzielle Einsparungen bedeuten. Die Herausforderungen in der Anomalieerkennung sind vielfältig. Die Seltenheit des Auftretens, Heterogenität in den Anomalien und wenig initiales Wissen über die Anomalien, bevor sie das erste Mal auftreten, sind in fast jeder Anwendung zur Anomalieerkennung herausfordernd. Zusätzlich gibt es oft Herausforderungen, die abhängig vom Anwendungsbereich sind.
In vorherigen Beiträgen haben wir bereits eine Einführung in das Thema Anomalien und die Relevanz einer schnellen Erkennung gegeben sowie Ansätze für die Anomalieerkennung in Zeitreihen vorgestellt, in denen wir auf die Fragen nach dem korrekten Algorithmus eingegangen sind bzw. wie sich mithilfe der Anomalieerkennung Maschinenausfälle vermeiden lassen.
Zusammengefasst sind Anomalien Datenpunkte, die selten, und oft nicht vorhersehbar sind. Konkretere Definitionen sind oft bezogen auf den Kontext oder die verwendeten Datenstrukturen. Von diesen Definitionen hängt teilweise auch ab, welche der vielen möglichen Verfahren am besten geeignet ist. Neben der Erkennung bekannter Arten von Anomalien kann auch die Identifikation bislang unbekannter Arten Ziel eines Anomalieerkennungsverfahrens sein. Das ist jedoch schwieriger und nicht alle Verfahren eignen sich dafür.
Outlier Detection beziehungsweise Ausreißererkennung oder Novelty Detection werden häufig synonym zu dem Begriff Anomalieerkennung verwendet. In der Praxis gibt es eine große Notwendigkeit für Anomalieerkennung in fast allen Bereichen, beispielsweise in der medizinischen Bilddiagnostik, bei der frühzeitigen Erkennung defekter Maschinen oder von Angriffen auf Netzwerke. Mit dem Anwendungsfall der Anomalieerkennung im Netzwerkverkehr beschäftigen wir uns derzeit in einem BMWK-geförderten Forschungsprojekt.
Herausforderungen in der Anomalieerkennung
Die Herausforderungen in der Anomalieerkennung sind vielfältig. Die Seltenheit des Auftretens, Heterogenität in den Anomalien und wenig Wissen über die Anomalien, bevor sie das erste Mal auftreten, sind in fast jeder Anwendung zur Anomalieerkennung herausfordernd. Zusätzlich gibt es oft Herausforderungen, die abhängig vom Anwendungsbereich sind.
Für den Netzwerkverkehr erschweren beispielsweise die dynamische Art und das Rauschen in den Daten die Anomalieerkennung, das heißt der Netzwerkverkehr kann sich ständig verändern und in der Datenübertragung kann es beispielsweise auch immer mal zu Störungen kommen. Das spiegelt sich in den Daten, die für die Identifikation der Anomalien genutzt werden, wider und kann das Unterscheiden dieser normalen Vorkommnisse gegenüber Anomalien erschweren. Immer wichtiger wird auch die Erklärbarkeit der Anomalieerkennungsverfahren, das heißt die Fähigkeit eines Modells Anhaltspunkte zu liefern warum bestimmte Datenpunkte als Anomalien identifiziert wurden. Abhängig von der verwendeten Methode zu Anomalieerkennung unterscheiden sich auch die geeigneten Ansätze für die Erklärbarkeit. Viele Ansätze im Bereich der Explainable AI (XAI) sind derzeit zugeschnitten auf das genutzte Modell. Es gibt nur wenige modellunabhängige und gute Verfahren. In welchem Maße und wie ein Modell Erklärungen erzeugen kann, ist daher oft noch individuell und modellabhängig.
Deep Learning für die Anomalieerkennung
Ein manuelles Erkennen von Anomalien ist nicht nur aufgrund oft hoher Datenmengen nicht realistisch umsetzbar. Auch das Festlegen von Kriterien zur Einstufung eines Datenpunktes als Anomalie ist häufig schwierig. Es gibt es gute Gründe Machine-Learning-Verfahren zur Anomalieerkennung zu nutzen.
Klassische Vertreter dieser Verfahren tendieren jedoch zu schlechten Ergebnissen auf hochdimensionalen Daten, wie sie im Netzwerkverkehr häufig auftreten. Daher sind sie für einen Teil der Anwendungen nicht optimal geeignet.
Ansätze, die Neuronale Netze nutzen, und damit dem Bereich des Deep Learnings zugeordnet werden können, liefern in diesen Fällen bessere Ergebnisse. Das Ziel und die Stärke der Neuronalen Netze ist das Lernen einer verbesserten Merkmalsrepräsentation. Autoencoder sind eine Form von Deep Learning Modellen, die hervorragend für Anomalieerkennung geeignet ist. Sie können in zahlreichen Variationen eine gute Erkennungsleistung für Anomalien erreichen.
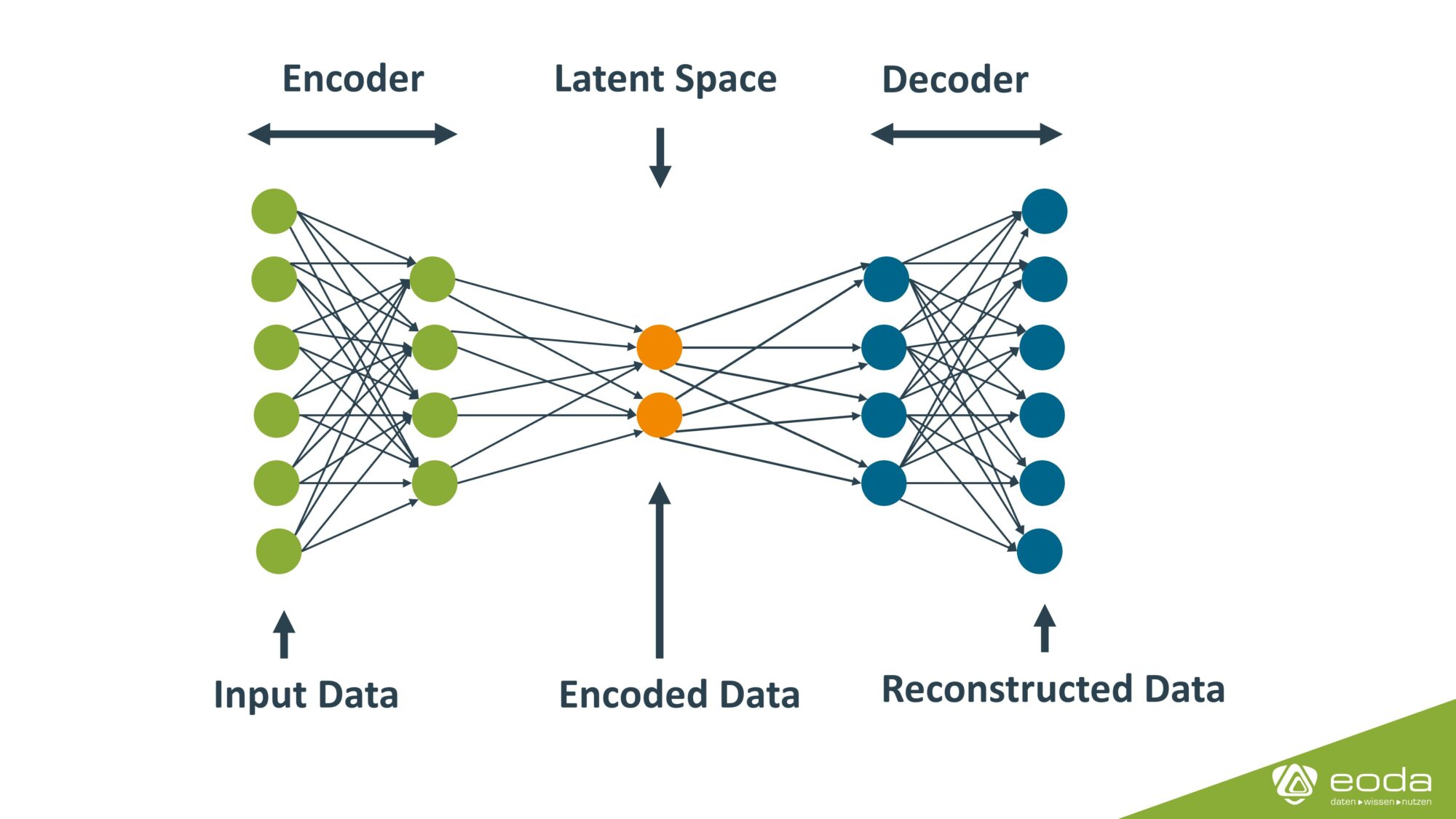
Das Ziel eines Autoencoders ist nicht spezifisch die Erkennung von Anomalien, sondern eine möglichst genaue Rekonstruktion der Eingabedaten.
Dafür besteht der Autoencoder aus einem Encoder und einem Decoder. Im Encoder wird über eine oder mehrere Schichten die Anzahl der Dimensionen der Daten verringert. Die Daten werden durch den Encoder also vereinfacht. Der Decoder erhöht die Anzahl der Dimensionen wieder schrittweise auf die ursprüngliche Zahl. Zwischen Encoder und Decoder befindet sich eine Schicht mit der internen Repräsentation der Daten, die oft auch als latent space oder bottleneck bezeichnet wird. In diesem haben die Daten die geringste Dimension. Im Training wird die Unterschiedlichkeit von den Eingabedaten und ihrer Reproduktion durch den Autoencoder für die Verbesserung der einzelnen Schichten und deren Einheiten benutzt.
In der Anomalieerkennung können Autoencoder vielfältig eingesetzt werden. Ein simple Vorgehensweise basiert auf der Annahme, dass anomale Daten in einem trainierten Autoencoder einen höheren Rekonstruktionsfehler, also eine größere Abweichung zwischen Eingabedaten und rekonstruierten Daten, aufweisen als normale Daten.
Hierfür wird der Autoencoder nur mit normalen Daten trainiert, bis die Rekonstruktion zufriedenstellend funktioniert. Nun kann die Verteilung der Rekonstruktionsfehler auf jeweils getrennten Mengen an normalen und anomalen Daten untersucht werden. Das ist beispielhaft in der Grafik abgebildet.
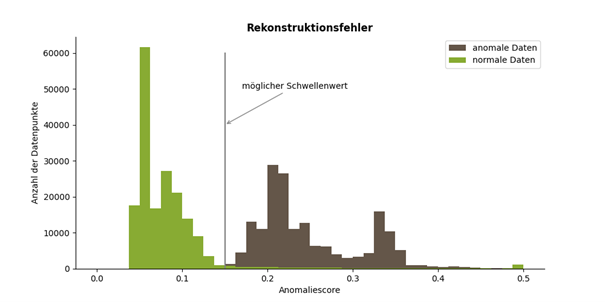
Basierend darauf wird ein Schwellenwert ermittelt, so dass die Mehrheit der Datenpunkte richtig klassifiziert wird. In der Vorhersage neuer Datenpunkte werden alle Datenpunkte mit Reproduktionsfehler größerer als der Schwellenwert als Anomalien erkannt. Dieser Ansatz kann weiter verfeinert und optimiert werden, so dass sich die Rekonstruktionsfehler von anomalen und normalen Daten deutlicher unterscheiden. Der Nachteil dieses Ansatzes liegt darin, dass er nur verwendet werden kann, wenn ein ausreichend großer Datensatz mit Klassenlabels vorliegt. Außerdem muss eine Entscheidung über den genutzten Schwellenwert getroffen werden, die maßgeblich die Qualität der Ergebnisse beeinflusst. Das führt dazu, dass oft andere Autoencoder-Ansätze verwendet werden.
Ein weiterer beliebter Ansatz nutzt die latente Repräsentation der Daten zwischen Encoder und Decoder und trainiert mit der dort vorliegenden Datenrepräsentation einen Klassifikationsalgorithmus. Die Idee hier ist, dass die vereinfachte Datenrepräsentation es ermöglicht auch klassische Machine-Learning-Verfahren wie Support Vector Machine (SVM) oder Random Forest sinnvoll zu benutzen, für die die Originaldaten beispielsweise zu hoch-dimensional waren. Die Funktion des Autoencoders in diesem Ansatz ist somit die Vereinfachung der Daten.
Es gibt viele weitere Variationen von Autoencodern für die Anomalieerkennung um die Erkennungsleistung weiter zu verbessern. Auch die Kombinationen mit anderen Ansätzen, wie beispielsweise Long Short-Term Memory (LSTM) oder dem Attention-Mechanismus sind beliebt. Der jeweils beste Ansatz ist stark abhängig vom individuellen Kontext der Anomalieerkennung.
Verwandeln Sie Ihren Datenpool in Vorteile!
Konzeption, Datenmanagement, Modellbildung, Produktivsetzung: Wir realisieren Ihre Datenprojekte von der Idee bis zur Implementierung der Lösungen in Ihre Unternehmensprozesse.