Was ist Data Preparation und warum ist sie für Unternehmen wichtig?
Wir leben in einer Ära der Digitalisierung, in der Daten und ihre Bedeutung für Unternehmen immer größer werden. Damit Business-User auf allen Organisationsebenen Erkenntnisse gewinnen können, benötigen sie zunächst Zugriff auf diese Daten. Nur so können sie aktiv an den Verbesserungen von Prozesse mitwirken.
Mit anderen Worten: Die Bedeutung der Demokratisierung von Daten und deren Analyse hat zugenommen und ist zu einer Anforderung für jedes Unternehmen geworden, um schnell und effizient Mehrwert aus Unternehmensdaten generieren zu können.
Heutzutage tragen die zunehmend volatilen gesättigten Märkte dazu bei, die Komplexität des Geschäftsumfelds zu erhöhen und machen es für Unternehmen noch schwieriger, mit einigen ihrer Konkurrenten auf dem Markt Schritt zu halten. Daher ist einer der wichtigsten Schritte für die Organisation, eine effiziente und agile Datenaufbereitung zu erreichen. Die Datenaufbereitung (Data Preparation) gilt als Schlüsselfaktor für jede Organisation, um diese zur Optimierung von Geschäftsprozessen zu nutzen und/oder neue und innovative datengetriebene Geschäftsmodelle zu ermöglichen.
Mit der steigenden Komplexität der Analysen ist es für Unternehmen immer schwieriger geworden, Erkenntnisse zu gewinnen und ihre Daten entsprechend den Änderungen der Marktbedingungen zu aktualisieren. Diese Herausforderungen setzen Organisationen unter hohen Druck, da die Bereitstellung von Daten für eine eingehende Analyse sowohl erfahrene Business-User, die die entsprechende Expertise über den Markt besitzen, aber auch Datenexperten erfordert, die die entsprechenden Prozesse mit neuen, modernen Ansätzen umsetzen.
Was bedeutet Datenaufbereitung für Unternehmen?
Da die Komplexität der Daten stetig zunimmt, benötigen Business-User flexible und neue Funktionen, um in Echtzeit und effizient auf ihre Daten zugreifen zu können sowie diese für die Analyse vorzubereiten. Die Datenaufbereitung ist daher ein Prozess, bei dem Rohdaten der Organisation erfasst und für jeden Business-User zur weiteren Analyse, z.B. in BI- oder Analyseplattformen, nutzbar gemacht werden. Recht häufig geschieht in Unternehmen die Datenaufbereitung noch zentral in den IT-Abteilungen. Aktuell findet hier jedoch auch eine Verschiebung in Richtung Self-Service– bzw. Augmented-Analytics statt.
Dabei stellt Augmented-Analytics den nächsten Schritt von Self-Service-Analytics dar.
Eine Augmented-Analytics-Plattform unterstützt u.a. bei Prozessen wie der Datenaufbereitung, so dass User diese selbst gestalten und automatisieren können. Mit solchen Plattformen wären dementsprechend auch andere Abteilungen in Zukunft in der Lage für ihre Datenanalysen entsprechende Pipelines zur Aufbereitung umzusetzen.
Datenaufbereitungsprozess
Die Herausforderungen des Datenaufbereitungsprozesses unterscheiden sich je nach Branche, Organisation und vor allem Bedarf. Der Rahmen dafür bleibt für die meisten Organisationen weitgehendst gleich.
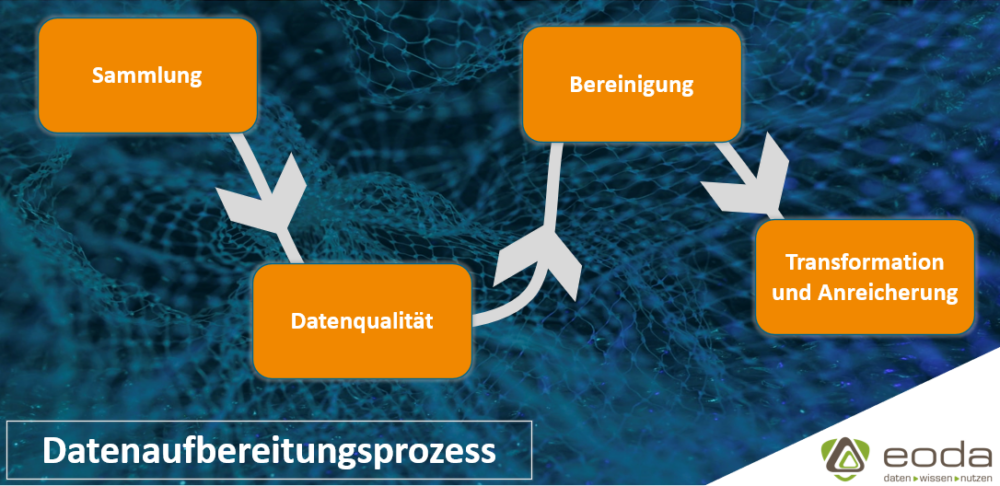
1. Datensammlung
Der Datenvorbereitungsprozess beginnt mit dem Auffinden und Sammeln relevanter Daten. Diese können sowohl aus bereits strukturierte und robuste Datenquellen wie Datenbanken, Data Warehouses/ Lakes oder ähnlichen Datenquellen innerhalb des Unternehmens stammen, als auch aus Daten in Form von Excel-Files, SAP-Reports usw. die gegebenenfalls erst identifizieren werden müssen.
Dabei ist es wichtig, sich im Vorfeld die Relevanz und die Eignung der vorzubereitenden Daten durch die entsprechenden ExpertInnen bestätigen zu lassen.
2. Datenqualität
Nach dem Sammeln der Daten ist es wichtig, die Datenqualität zu untersuchen. Dadurch erhöht sich nicht nur das Verständnis für die Inhalte, es lässt sich auch abschätzen, wie hoch der Aufwand ist, die Daten in einen bestimmten Kontext zueinander zu bringen. Dazu gehört sowohl die Identifizierung von Datenmustern, Beziehungen und anderen Attributen in den Daten. Auch müssen weitere Kriterien der Datenqualität betrachtet werden. Dies enthält die Prüfung nach Vollständigkeit, Korrektheit, Konsistenz, Redundanzfreiheit, und Relevanz der Datenwerte, um weitere Optimierung der Datenqualität zu ermöglichen.
3. Datensätze bereinigen
Die Bereinigung der Datensätze ist ein entscheidender Teil des Datenvorbereitungsprozesses. Hierbei werden fehlerhafte und unnötige Daten entfernt, fehlende Werte aufgefüllt und die Daten an ein standardisiertes Muster angepasst. Ziel ist es vollständige, konsistente und genaue Datensätze zu erhalten. Danach erfolgt das Integrieren und Verknüpfen der bereinigten Daten aus allen Datenquellen in einem Data Lake/ Warehouse, damit die Daten im nächsten Schritt, z.B. in entsprechenden Plattformen, analysiert werden können.
4. Datentransformation und -Anreicherung
Bei der Transformation werden die Daten in ein einheitliches und verwendbares Format umgewandelt (z.B. kann durch das Erstellen neuer Felder oder Spalten, die die Werte aus vorhandenen Daten aggregieren). Dazu gehört die Aktualisierung des Formats und der Datenwerte, um ein klar definiertes Ergebnis zu erzielen oder die Daten für alle Business-User der Organisation verständlicher zu machen.
Das Anreichern von Daten bezieht sich auf das Hinzufügen, Optimieren und Verbinden von verbundenen Datensätzen mit weiteren relevanten Informationen, damit tiefere Einblicke und detaillierte Erkenntnisse ermöglicht werden.
Fazit
Die Datenaufbereitung erstellt qualitativ hochwertigere Daten zur Unterstützung der Business Analysten und Data Scientists, indem verschiedene Arten von Daten für ihre Analysezwecke aufbereitet werden. Das erfolgt in einem Prozess, indem Fehler korrigiert und Rohdaten normalisiert werden, bevor sie verarbeitet werden können. Die Datenaufbereitung ist ein sehr wichtiger Schritt für jedes Unternehmen, nimmt jedoch viel Zeit in Anspruch und erfordert möglicherweise spezifische Fähigkeiten und Tools, um die Datensätze vorzubereiten. Aber mit dem richtigen Datenvorbereitungstool und Expertise ist der Prozess schneller, effizienter und für alle Business-Users zugänglicher.
Weitere Themen

Unsere Services:
Data Consulting & Projects
ließen Sie mit künstlicher Intelligenz und Machine Learning das Datenpotenzial Ihres Unternehmens und schreiben Sie Ihre eigene digitale Erfolgsgeschichte. In unserer Strategieberatung zeigen wir Ihnen wie.

Blog
Data-Science- & KI-Projekte: Die Vorteile im Überblick
Von der Erhöhung der Datenqualität bis zur Optimierung von Produkten & Services: Erfahren Sie mehr über die Mehrwerte, die für Sie im Rahmen eines Data-Science- & KI-Projekts entstehen können.

Case Study:
Künstliche Intelligenz in der Rechnungsprüfung
Intelligente Algorithmen als Buchhalterhilfe zur Automatisierung des Rechnungseingangs für die B. Braun Melsungen AG.

Data-Driven Software:
Die Plattform, die Analytics mit Usern verbindet
Unsere Lösung YUNA: Modulare, belastbare und skalierbare Architektur und Features, die alle relevanten Schritte zur Konzeption, Ausführung und Verwaltung digitaler Services!